안녕하세요 마무입니다~오늘 배울 "
리눅스 find 명령어"라는 명령어는 영어 뜻 그대로
"파일을 찾는 명령어" 입니다.
그리고 "
리눅스 와일드카드"와 "
리눅스 따옴표", "
리눅스 특수기호"에 대해서도 매우 자세히 다룰 예정입니다.
당연히 실제로도 리눅스 내에서 정~말 자주 사용되며, 그렇기에 반드시 알아야 하는
그런 명령어라고 할 수 있습니다!
오늘 여려분들이 이 포스트를 다 읽으면, 명령어 "find"에 대한 거의 모든 의문이 사라지며,
여러분들이 못 찾는 파일이 없어질 것입니다!
백문이 불여일견! 긴 말이 필요 없겠죠? 바로 목차 알려드리겠습니다!
--목차--
1. find [장소] {[조건] [조건 값]}.....
2. -name ['찾을 이름']
i) 와일드카드( *, ?, [], {} )의 의미
ii) ' ', " "(작은, 큰 따옴표, single, double quotes)의 의미와 쉘의 명령어 처리 순서
iii) 왜 와일드카드를 사용할 때 따옴표를 같이 안쓰면 오류가 발생하는가?
3. -user [찾을 소유자이름], -ls(우리가 아는 ls)
4. -group [찾을 그룹소유자 이름]
5. -type [찾을 파일 타입]
6. -size [+-(이상, 이하)크기(c, k, M)]
7. -newer [파일이름]
8. -empty
9. -perm [-찾을 권한번호이 포함된 파일]
10. -exec [명령어] {} \;
i) -exec 에서 왜 []를 못 쓰는가
ii)왜 ";"가 아닌 "\;"인가?
11. find -ok [명령어] {} \;
---------
입니다.
여기서 못 찾은 정보는
운영체제 독학 페이지 :
https://mamu2830.blogspot.com/p/blog-page_14.html
리눅스 독학 페이지 :
https://mamu2830.blogspot.com/p/blog-page_13.html
에서 찾아보세요!
1. 리눅스 find 형식
제일 먼저,
"find"의 명령어 형식은
"find [파일을 찾을 장소] {[조건] [조건 값]}..... "
입니다.
물론 원랜 "조건"이 아니라 "표현식" 이라 하는데,
저는 표현식이라고 하면 잘 안외워지고 어색하기에 "조건"으로 바꿔서 외웠고 이 포스트에서
"조건"이라 표현할 것입니다.
제 포스트들에서 자주 등장하는 표현중 하나인,
"....."은 앞에 내용
"{[조건] [조건 값]}"을 원할 시 반복해서 더 넣을 수 있다는 뜻입니다.
"조건"이라는 것은 이제 제가 붙인 이름인데,
"-name", "-user"와 같은 형태를 가리키는 말입니다. 보통 "-name(
이름이 ~~인)" "-user(
소유자가 ~~인)" 이런식으로 생각하시면 사용하기 편합니다.
"조건 값"이라는 것은 앞의
조건에 해당하는 값들을 말합니다. 예를 들자면 조건이
"-name(이름)"같은 경우, 뒤에 오는 "조건 값"은
"파일이름"일 것이고,
"-user(소유자)"같은 경우 "조건 값"이
"유저 이름"이겠죠
그런데 중요한 건, 리눅스 명령어에서
"옵션"은 순서가 중요하지 않았지만 이
"find" 같은 명령어에서 사용하는 이런
"조건"은,
앞에서부터 순서대로 처리 합니다.
앞에서부터 처리한다는 걸 예시를 통해 설명해볼게요.
find / -type d -name '?ab?' -ls -exec rm -r {} \;
이렇렇게 "find"명령어를 쳤을 때 실행되는 순서는
(파일을 찾겠다) (/에서) (타입이 디렉토리이고) (이름은 4글자 중 가운데가 ab며)
(앞의 결과를 "list" 형태로 보여주고) (그 결과 나온 파일들을 하위 파일까지 지워라)
이런 식으로
앞에서부터 처리가 된다는 겁니다. 그래서 조건이 앞에서부터 실행이 되니, 자기가 찾고싶은 파일을 찾을 때
조건 순서를 잘 고려해야 합니다.
아 물론
"-exec rm -r {} \;"은 뭔가요??
라는 질문이 바로 생각나실 겁니다.
저거는 제가 이름 붙인 거지만, 명령어를 실행하는
"명령 조건"이라고 합니다.
앞서 조건들로 찾은 파일들에게, 어떤
명렁어를 추가적으로 실행하고 싶은 경우 사용하는 조건들이죠.
꼭 써야할 필요는 없지만, 쓸 경우 말했다시피
"찾은 파일"에 대해서 명령어를 수행하기 때문에 조건들 중 맨 마지막에 써야합니다.
이건 이따가 자세히 다룰 것이므로, 여기서 심각하게 생각하실 필요 없어요~
알고보면 그리 어렵지도 않고요! 마음 가볍게 하고 이제 본격적으로 조건들에 대해서
알아보겠습니다!
2. find -name ['찾을 이름']
자 이제 본격적으로
"find"명령어를 사용하려면
조건을 알아야죠?
제일 먼저 배울 조건은 가장 많이 사용하는
"-name"으로
영어
name(이름)에 걸맞게, 뒤에 "조건값"으로 적은 "이름"과 매치되는 파일을 찾습니다.
-형식-
-name [파일이름]

이렇게
"find(찾겠다) /(최상위 루트디렉토리에서) -name(파일 이름이) a(a인 것을)" 하니
"a"라는 이름을 가진 파일이 나오죠?
이런 식으로
"정확한"이름을 알고 있어서 파일을 찾을 수 있다면 이렇게만 써도 됩니다만,
실제로 저희는 무언가를 찾을 때는
정확히 이름을 다 아는 경우가 적잖아요? (엄청나게 긴 이름의 파일들도 많으니까..)
그래서 전체 이름을 모를 때, 파일을 찾기 위해 사용하는 것이 바로
"와일드 카드" 입니다.
i) 리눅스 와일드카드( *, ?, [], {} )의 의미
"와일드카드(wildcard)"란
"될 수 있는 값이 여러 개인 것"이란 뜻으로 사용이 됩니다.
트럼프 카드게임 종류에서,
모든 카드로 사용이 가능한 조커를
"와일드카드"라고 하며
저희들이 대부분 즐겨하는 리그오브레전드의 "트위스티드 페이트"란 캐릭이 사용하는
"W"스킬 (
파랑,
빨강,
노랑 중 하나로 바뀔 수 있는)
의 이름도 "와일드카드"죠.
이처럼
"와일드카드"란
"될 수 있는 값이 여러 개인 것"이란 의미로 저희 삶 곳곳에서
사용이 되는데요, 당연히 일상 뿐만 아니라 컴퓨터 공학에서도 사용됩니다. 바로
무언가를 검색할 때, 더욱 빠르고 수월하게 검색하게 해주는 역할로 말이죠.
물론 여기서
"될 수 있는 값이 여러 개인 것"이란 의미가
어떻게 "검색을 더 빠르게 해주는 역할"로 바뀌어 사용이 되는 지 의문이 들 것 입니다.
예시를 들어 대답하자면, 저희들이
가장 흔히 볼 수 있는 와일드카드엔 "모든 값"이란 의미의
"*"이 있는데, 저희들이 평소에도 많이 사용해 왔었죠?(ls /dev/sd*와 같이)
이 "
모든 값"이란 건 "될 수 있는 값이 여러 개인 것"이기에
가능했던 일이 아닙니까? 그래서 이런식으로
"모든 값"의 의미를 가진
"*"도 와일드카드 범주에 들어가는 것이고, 원랜 파일 이름 하나하나 적어서 명령어를 수행하거나 찾아 오래걸릴 것을,
"모든 값"이란
"와일드카드, *"를 사용하면 더욱 쉽고 빠르게 수행(검색)할 수 있죠.
그래서 "될 수 있는 값이 여러 개인 것"이란 "와일드카드"란 개념이, 무언가를 검색할 때 더욱 빠르고 수월하게 해주는 역할이라고 했던 것입니다.
마찬가지로
"*"뿐만 아니라 "될 수 있는 값이 여러 개인 것" 의미를 가진 기호들은 모두 "와일드카드"라고 보시면 되고,
무언가를 검색할 때 수월하게 해주는 역할이라는 것을 아시면 됩니다.
자 그럼 이런
"될 수 있는 값이 여러 개인 것"인
와일드카드에 무엇이 있는지 알아볼까요?
"*" : "모든"이란 의미를 가지고 있습니다.
--예시--
'ade*' = ade로 시작하는 모든 파일
'*ade' = ade로 끝나는 모든 파일
'a*b' = a로 시작해서 b로 끝나는 모든 파일
--------------------------------------------------------------------------------------------
"?" : "모든 한 글자"란 의미를 가지고 있습니다.
낯선 기호라 감이 잘 안오실텐데, 그냥 "?" 한 자리에 들어갈 수 있는 모든 글자라고 보시면
됩니다.
--예시--
'??a??' = 총 5글자인데 가운데가 a인 모든 파일
'bd?' = bd로 시작하는 모든 3글자 파일(ex:
bda, bdb, bdc, bdd,...bd1, bd2,... bd_,..)
'?bd' = bd로 끝나는 모든 3글자 파일
--------------------------------------------------------------------------------------------
"[]" : "[]안에 있는 모든 한 문자"란 의미를 가지고 있습니다.(될 수 있는 값이 여러 개)
이것도 말로는 감이 잘 안오실텐데, 예시를 보시면 감이 오실 겁니다.
--예시--
'[.abc,]' = . a b c ,
'[de]a[cf]' = dac daf eac eaf
'[*]a' = aa, ba, ca,...,1a, 2a,....Aa,..., .a, ...
"[ab]" 이렇게 쓰면 될 수 있는 값이 "a", "b"로, 한 개가 아니죠? 그래서 와일드카드!
-------------------------------------------------------------------------------------------
"{}" : "{}안에 있는 모든 한 단어"란 의미를 갖고 있습니다. (될 수 있는 값이 여러개죠?)
참고로
[]는 문자 단위로 취급하고,
{}는 단어 단위로 취급한다는 것이 차이점입니다.
차이점을 와닿게 하기 위해 예시를 들어볼게요!
[a,b,cde] = , a b c d e
{a,b,cde} = a b cde
이렇게 보니 "문자 단위로 취급하는 대괄호"와 "단어 단위를 취급하는 중괄호"의
차이가 느껴지시나요?
대괄호와 중괄호의 차이점을 알았으니 이제 중괄호만의 예시를 통해
중괄호의 특징을 한번 보겠습니다.
--예시--
a{0,4,3} = a0 a4 a3
a{0,1}b = a0b a1b
a{0,1}{1,2,3} = a01 a02 a03 a11 a12 a13
touch /home/mamu/{ab, ad} = touch /home/mamu/ab, touch /home/mamu/ad
아 그리고
추가로 알아야 할 중괄호{}의 특징이 한 가지 더 있습니다.
위에서 말했다시피
"중괄호{}"는 단어 단위로 구분을 하는 기능이기에
"{abc}"처럼 단어 하나만 들어있거나, {}처럼 아무것도 안 들어있는 경우,
"중괄호{}"는 "아무런 기능이 없는 문자 {}"로 취급이 됩니다.
무슨 소리냐면
"touch {abc,def}"같이 중괄호 안에 단어가 여러 개면 "abc" "def"란 2개의 파일을
만들지만,
"touch {abcdef}"같이 중괄호 안에 단어가 하나라면, "{abcdef}"와 같이 중괄호를 포함한 이름의 파일을 하나 만듭니다.
"touch {}"같은 경우도 위 사례처럼, 그냥 아무의미 없는 문자로 취급돼 "{}"란 이름의 파일이 만들어집니다.
-------------------------------------------------------------------------------------------
대표적으로 파일을 찾을 때 사용되는 와일드카드들은 이 정도 있습니다.
물론 여기서
맹점이 있으니.. 그것은 바로
find -name 명령어에서 와일드카드를 사용할 시 무조건 '나 "를 같이 사용해야 한다는 것
눈치가 빠르신 분들은 위에서 제가 와일드카드 예시를 보여드릴 때
모두
'[글자들]'와 같이
' '를 사용한 것을 보셨을 겁니다.
권유가 아니라 반드시 와일드카드를 find에서 쓸 시
' 나
"를 붙여야 하는게,
안 붙일 시 잘못 된 값이 나오거나 에러가 뜹니다.

이렇게 말이죠. 자 그럼
어떤 원리로 이런 에러가 발생하는 지, 또
왜 '와 "를 써야하는 지
설명해 드리겠습니다!
ii) ' ', " "(작은, 큰 따옴표, quotes)의 의미와 쉘의 명령어 처리 순서
일단 에러 발생원리를 이해하려면 "따옴표(quotes)의 의미"와 "쉘의 명령어 처리 순서" 를 알아야 합니다. 그러니 이해하고 알아보겠습니다.
제일 먼저,
' '(single quotes)란 한국말로
"작은 따옴표"죠?
이
' '를 이용해
리눅스에서 문장을 감쌀 시, 감싸진 문자들은
모두
쉘에서 "아무런 의미도 없는 일반 문자 취급"합니다 ex) '*abv' : 그냥 이름이 *abv란 파일
무슨 소리냐면,
'로 문자들을 감쌀 시, 앞서 설명한
"와일드카드"나 아직은 안 배운
"환경변수를 호출하는 $"와 같은 ,
"기능을 가진 모든 기호"들을
쉘에선 그냥 순수한 문자 취급한다는 것이죠.
아직은 안 배웠지만
명령어를 찾는 경로가 등록된 "PATH라는 환경변수"를
예시로 든다면

이렇게 그냥
"$"기호 없이 환경변수 PATH를 쓰면,
"echo"명령어가 환경변수 PATH가 아닌 그냥
순수한 문자 "PATH"로 인식합니다.

하지만
$PATH처럼 환경변수 호출 기능을 가진
기호 $를 붙이니,
"echo"명령어가 "환경변수 PATH"로 인식하죠.
그런데 사실 이 과정은 "echo"가 환경변수를 인식한게 아니라
"쉘"이 환경변수를 인식하고 치환한 값을 "echo"가 넘겨 받은 것이였습니다.
그 과정을 좀 더 자세히 말하자면 이렇게 됩니다.
리눅스 쉘 해석 순서
1. 쉘(shell)이 띄어쓰기를 보고 단어들을 인식한다
2. 쉘이 단어들 중 와일드카드나, 환경변수, 특수기호가 있나 명령어를 확인한다
3. 쉘이 환경변수 호출기호 "$"가 붙은 "PATH"가 환경변수라는 것을 인식
4. 환경변수에 "PATH"라는 것이 있나 확인하고, 찾을 시 "환경변수 PATH의 값"을 "$PATH"대신 넣음
5. 명령어 "echo"를 실행하고, 명령어 "echo"는 치환된 "환경변수 PATH의 값(/usr/local/bin:/bin:/bin:.......)"들을 인식하고 그대로 화면에 출력함
이런식으로 쉘은 와일드카드나 환경변수, 특수 기호를 먼저 처리를 한 뒤에,
명령어를 처리한다는 것인데
이걸 설명한 이유는 '나 "를 안 붙일 시 에러가 발생하는 게 바로 이 쉘이 명령어를 해석하는 순서 때문에 생기는 거라서
그렇습니다. 좀 더 자세하게는 "iii)"에서 알려드리겠습니다!
계속해서 이번엔 '$PATH' 와 같이 '
따옴표'를 붙이면 어떻게 바뀌는 지 봐볼까요?

이렇게
' ' 를 붙이니 "쉘"이 "$기호"를 인식을 못했기에, "echo"는 순수하게 문자 그대로의 "$PATH"로 인식하고 화면에 출력한 것을 볼 수 있습니다.
이렇듯
작은 따옴표(single quotes)는
쉘이 의미있는 기호를 그냥 문자로
처리하게 만듭니다.
그렇다면 바로 또 궁금한 게 생기죠 바로 비슷하게 생긴
"큰 따옴표"는 작은 따옴표와 뭐가 다르냐? 라는 의문이 말이죠!
큰 따옴표 " "(double quotes)같은 경우엔
작은 따옴표 ' ' 와 다르게 "$(dollar), `(back quote 또는 grave), \(escape)"만 쉘이 처리할 수 있게 합니다.
즉 ""로 문자를 감싸면 $PATH와 같은 "환경변수"나 "`, \"가 붙은 문자들은 쉘이 인식할 수 있다는 것이죠.
큰 따옴표가 허락하는 이 기호들($ ` \)의 특징은 바로 변수들을 사용할 때 사용하는 기호들이라는 겁니다. 쉘 프로그래밍을 안 배운 저희들 입장에선 이 정도만 알고 갑시다~

이렇게
큰 따옴표(")는
작은 따옴표(')와 다르게 쉘이 $(dollar)가 붙은 환경변수를 인식하게 해주죠
그럼 이번에
와일드카드로도 한번 실험을 해볼게요

이렇게 기존에
와일드카드 "*"를 사용할 시, 쉘이 와일드카드를 명령어 "echo"보다 먼저
인식하여 처리해, "a, ab, ac, ad" 와 같이
제가 만들어 놓은 "a로 시작하는 파일의 이름들"을 "a*" 대신 넣습니다.
그리고 나서 "echo"를 실행하니, 그 파일 이름들(a, ab, ac, ad an...)을 "echo" 명령어가 인식하여 그대로 출력한 것이죠
하지만

이렇게
"a*"처럼 큰 따옴표를 붙이니,
쉘이 와일드카드를 인식을 못하고 "echo"에게 그대로 a*를 넘깁니다. 그래서 "echo"는 a*이라 출력을 한 것이죠.
여기까지 "큰 따옴표"는 "$(dollar), `(back quote 또는 grave), \(escape)만 쉘에게 허락한다는 것을 알려드린 겁니다.
이렇게만 보면 "큰 따옴표"는 되게 복잡하고 짜증나는데, 큰 따옴표의 진가는 여러분들이 쉘 스크립트(코드)를 짤 때 느낄 수 있을거에요 ㅎㅎ
자 되게 길게 이야기 했는데, 그럼 이제 본격적으로
왜 find -name에 '와 "를 써야하는 지
설명하겠습니다!
iii) 왜 와일드카드를 사용할 때 따옴표를 같이 안쓰면 오류가 발생하는가?
일단 증상을 보기 위해,
'와 "를 사용하지 않고 와일드카드를 이용해 파일을 찾아볼게요

자
주황색 1번으로 표시한
와일드카드 * 같은 경우 따옴표가 없으니 에러가 납니다.
그 다음
초록색 2번으로 표시한
와일드카드 ? 같은 경우에도 따옴표가 없으니 에러가 나죠.
하지만 파란색 3번으로 표시한
와일드카드 [] 같은 경우 에러가 안납니다.
같은 와일드카드인데 왜 어떤 건 되고 어떤 건 안될까요?
그 이유는 바로 제가 앞에서 설명한
"쉘"의 명령어 처리 순서 때문입니다. 한번 위의 와일드카드들을 정밀하게 분석해볼게요!
1번 주황색 *인 경우,

이렇게
현재 디렉토리에 a로 시작하는 파일들이 2개 이상입니다. 이게
에러의 원인이 된겁니다.
무슨 소리냐면
"-name" 조건은 "조건 값"을 1개 밖에 못 받습니다.
하지만 저희가
find / -name a* 와 같이 따옴표 없이 와일드카드를 쓸 경우 쉘은 와일드카드를 제일 먼저 처리하여 현재 디렉토리 내 "a로 시작하는 모든 파일들의 이름"을 "a*" 대신 넣고 find / -name 명령어를 실행합니다.
즉 find / -name a* 라고 칠 경우 이건
find / -name a ab ac ad anaconda-ks.cfg 이렇게 바뀌어 처리되는 것이죠.
그래서
당연히 "-name 조건 값"이 "여러개"니까 에러가 난 것입니다.
같은 원리가
초록색 2번인 와일드카드 ?에도 적용이 되어 에러가 난 겁니다.

이렇게 현재 디렉토리 내에 "a로 시작하는 2글자 파일"이 여러 개여서
쉘이 명령어
"find"보다 "와일드카드 ?"을 먼저 처리하기에 find / -name a? 이 아니라
find / -name ab ac ad 로 처리가 되어 조건 값이 여러개라 오류가 난 것이죠.
반면에
파란색 3번인 와일드카드 [] 인 경우
참고로
[a-d]처럼 대괄호와 "-"를 같이 쓰인 경우에는
"a부터 d까지"란 의미가 있습니다.
즉,
[a-d]는 "a b c d" 인 것이죠! 그냥 그런게 있구나~ 하고 넘어갑시다. 이런 기호들의 특징들은 다른 포스트에서 집중적으로 다루겠습니다!
자 다시 돌아와 사진을 보시면
현재 디렉토리 내에 [a-d] 와일드카드에 해당하는 파일이
"a" 하나 뿐이라서
쉘이 와일드카드를 먼저 처리해도, -name 조건에 "a" 하나만 들어가기에
find / -name [a-d] 가
find / -name a 와 같이 바뀌어서 문제 없이 잘 처리가 된 것이였습니다.
물론 에러가 안 난 것뿐이지 실제로 저희가 원하는 결과는 아니지만 말이죠 (
우린 a가 아니라 리눅스 전체에서 a부터 d 이름의 파일들을 찾는 걸 원했기에)
자 그럼 저희는 이제 작은 따옴표(')와 큰 따옴표(")를 제대로 배웠기에 와일드카드를 제대로 사용하려면 어떻게 써야하는 지 이제 압니다.
네 그렇습니다.
1번인 경우 find / -name a* 가 아니라
find / -name 'a*' 또는 "a*" 로 해야하고
2번인 경우 find / -name a? 가 아니라
find / -name 'a?' 또는 "a?" 로 해야하고
3번인 경우 제대로 하려면 find / -name [a-d] 가 아닌
find / -name '[a-d]' 또는 "[a-d]"
를 쓰면 문제 없이 잘 작동할 겁니다.
1번인 경우 검색 되는 파일이 너무 많기에, 3번만 보여드리겠습니다.(2번은...?)

따옴표를 붙이니 우리가 원하는 결과가 제대로 나왔죠?
자 여기까지
ii)에서 배운 "작은 따옴표와 큰 따옴표 의미, 그리고 쉘 명령어 처리 순서"를
이용해 "iii) 왜 와일드카드를 사용할 때 따옴표를 같이 사용해야하는지" 를
이해한 겁니다.
와... 수 많은 조건들 중 하나 배우는데 왜 이렇게 긴지, 나머지는 어떡하냐 겁이 나시죠ㄷㄷ
걱정 마세요
"-name"만 진짜~ 긴 거고 나머지는 속전속결로 금방 끝날 겁니다!
물론 맨 밑쯤 "명령 조건"에선 다시 조금 길어지겠지만요 ㅎㅎ
좀만 더 힘냅시다! 제 포스트가 길어서 읽기 힘드시겠지만
솔직히 다 읽는데 40분도 안 걸리잖아요~
(학원에선 3시간정도 배웁니다, 아니면 대충 명령어만 따라하고 1시간만에 끝나거나)
또
포스트 내용을 전부 안 읽고,
명령어 형식과 조건만 대충 따라만 하고 넘어가신다면, 여러분들은
원리를 모르기에 자꾸 까먹고,
이후 "find"명령어 뿐만 아니라 다른 명령어, 쉘, 쉘 스크립트, 시험 준비과정에서 궁금한 게 끝도 없이 생겨나서
결국 이 포스트로 다시 돌아오시게 될 겁니다 ㅎㅎ
그러니
이번에 확실히 한번에 끝내고 간다고 생각하고 힘내서 읽어보자구요!
(물론 인간의 뇌는 한번만에 전부 외울 순 없지만요 핳핳)
3. find -user [찾을 소유자]
"-user" 조건은 영어 "user"의 뜻처럼, "조건 값"으로 "유저의 이름(소유자 이름)"을
넣습니다.

자 이렇게 "find / -user mamu" 라고 치니 소유자가 "mamu"인 파일들이 모두 나옵니다.
물론 이렇게만 보면 제대로 검색이 된 건지 모르죠?
그래서 저희는 바로
"-ls"라는 조건을 또 배우고 같이 사용해 볼겁니다.
"-ls(list)"는
우리가 아는 그 명령어 "ls(list)"와 같은 의미의 조건입니다. 그런데 이건
find 명령어용으로 만든 것으로, 굳이 말한다면
"ls"보단 "ls -l"와 비슷합니다.
또한
이 조건 "-ls"는 우리가 아는 "ls" 명령어처럼
옵션을 넣을 수 가 없습니다.. 그래서
이걸 쓰는 것보단 나중에
"명령 조건"에서 ls를 쓰는 것도 방법입니다
뒤에
"조건 값"을 넣을 필요 없는 조건으로,
앞의 조건이 검색한 파일들을 받아서 "ls"처럼 inode(자세한 정보들)을 보여줍니다.

이렇게 앞에서 했던 "-user mamu"에 "-ls"를 더해 검색하니 "inode"와 "inode번호"까지
나오며,
소유자 mamu 파일들이 잘 검색된 걸 알 수 있죠?
4. find -group [찾을 그룹]
"-group"이란 영어 group의 뜻처럼,
"찾을 그룹의 이름"을 "조건값"으로 넣습니다.

이렇게 뒤에 적은 그룹이 속한 파일을 찾습니다. "-ls"를 쓴 것은 이제 설명 안해도 되죠?
5. find -type [찾을 파일 타입]
"-type"란 영어 이름 대로,
"조건 값"에 "파일의 타입"을 넣습니다.
파일의 타입은
"파일과 디렉토리" 포스트에서 다뤘었죠?
(f{-},d,l,p,b,c,s)등등 말이죠
기억이 안나시거나 모르시는 분들은 보고 오시면 좋을 것 같습니다!
https://mamu2830.blogspot.com/2019/07/blog-post.html

이렇게 파일 타입중
블록파일(b)를 치니 블록 파일들이 잘 검색된 것을 볼 수 있습니다.
리눅스 운영체제는 파일크기를
"블록"이라는 최소 단위로 다룬 다는 것을
파일시스템 포스트에서 배웠었죠? 잘 모르시는 분들은
https://mamu2830.blogspot.com/2019/11/fdisk-df-etcfstab-blkid.html
보고 오시면 좋습니다~
일반 파일인 경우 "find -type"에서 찾을 때 "-"가 아닌
"f"를 써줘야 합니다~
6. find -size [+-(이상,이하)크기(c, k, M)]
"-size"도 이름 뜻대로,
"조건 값"에 "해당하는 크기의 파일을 찾는" 조건입니다.
"+"는 "이상"이란 뜻으로
"-size +10M" 이렇게 하면
"10M이상의 파일"을 찾으란 겁니다.
"-"는 "이하"라는 뜻으로
"-size -10M" 이렇게 하면
"10M이하의 파일"을 찾으란 겁니다.
물론
"+"나 "-" 중 아무것도 안쓰면 정확하게
뒤에 적은 사이즈 파일만 찾습니다.
그런데 여기서
정확한 사이즈의 파일을 찾고 싶으면 "바이트단위(c)"로 찾아야 합니다.
KB나 MB같이 단위가 들어간 경우,
정확한 파일만 찾는게 아니라 근삿 값까지 찾습니다.
파일의 사이즈의 단위는
c(Byte), k(KB), M(MB)가 있습니다만, 왜 "KB"는 "소문자 k"이고 "MB"는 "대문자 M"인지는 저도 잘 모르겠습니다.. 참 누가 만들었는지 ㅡㅡ...
일단 "Byte"가 소문자 "c"인 걸 외우는 방법은, 원래 "소문자 c"는 컴퓨터에서
"글자"를 뜻하는 "c(characters)"로 자주 쓰이거든요?
그리고
대부분 한 글자(character)당
2~4 Byte가 쓰입니다.
그리고
리눅스에서 "byte"단위같이 작은 용량이 쓰이는 경우는,
글자 외 거의 없습니다
(눈에 보이는 것들 중에선)
그러니 byte는 byte단위가 쓰일 만한 건 글자! c(character)! 이렇게 연상해서 외우시면
좋을 것 같습니다.
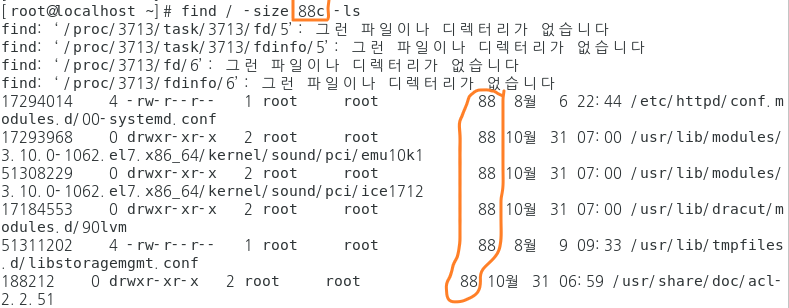
- 88byte 파일을 찾고 싶다? -
"find / -size 88c"
 - 10MB 이상 파일을 찾고 싶다? -
"find / -size +10M -exec ls -lh {} \;"
- 10MB 이상 파일을 찾고 싶다? -
"find / -size +10M -exec ls -lh {} \;"

명령 조건인 "-exec ls -lh {} \;"를 쓴 이유는
"-ls"는 보기 편하게 사이즈가 안나오기에
한 겁니다. 밑에서 설명할 것으므로 지금은 대충 넘어가 주세요!
- 10MB 이상이며 15MB 이하 파일을 찾고 싶다? -
"find / -size +10M -size -15M -exec ls -lh {} \;"

find(
찾겠다) /(
최상의 루트디렉토리에서) -size +10M(
사이즈가 10M이상이고)
-size -15M(
사이즈가 15M 이하인 파일을)
제가 말했던 것처럼 조건들의 순서만 잘 지켜주시면 어떻게 사이즈를 줘서 찾아야할 지
감이 자동으로 오실 겁니다 ㅎㅎ
7. find -newer [파일이름]
이것도 매우 쉽습니다.
"-newer"의 영어
new(최신의) + er(비교용 접미사) 뜻대로
"뒤에 적은 파일"보다 "더 최근에 만들어진 파일들"만 찾으라는 뜻입니다.
ex) "find / -newer [파일이름]"
이런식으로 사용하는 것인데, 아마 여러분들은 리눅스 시스템이 시간이 엉망이 되어있어서
이 명령어를 실행하면 원하는 값이 안나올 겁니다 ㄷㄷ
하지만 아직 제가 시스템 시간 맞추는 방법을 알려주지 않았다는 것...
이건 다음에 포스팅을 할 터이니 일단은 그런가보다~ 하고 넘어가주세요 ㅠㅠ
8. find -empty
"-empty(비어있는)"이란 뜻에 걸맞게
"아무것도 안 들어있는 파일을 찾는 조건"입니다.
일반 파일이라면
아무것도 안 쓰여있으니 크기가 0이고,
디렉토리 파일이라면 말 그대로
디렉토리만 있는 상태라 자체 크기 6바이트 크기입니다.
당연히
조건 값은 필요 없습니다!
이렇게
"find .("/"는 너무 파일들이 많기에)
-empty -ls"하니
 초록색으로
초록색으로 표시한 곳을 보시면
"d"라고 디렉토리라는 것을 알 수 있고 빈 디렉토리지만
디렉토리 자체의 기능때문에 6바이트 크기인 걸 알 수 있고
파란색 "-(f)" 일반파일인 경우
아무것도 안 쓰여있기에 0바이트인 것을 알 수 있습니다.
9. find -perm [권한 8진수]
"-perm(permissions)"도 영어 뜻 대로,
뒤에 적은 권한번호가 포함된 파일을 찾습니다.
저희가 권한공부를 할 때, 각 권한에 해당하는 번호를 외운 이유가 바로 이것 때문이였죠 !
여기서
중요한 것은 자기가 입력한 권한과 정확하게 같은 파일을 찾을거면, "-" 없이
그냥 권한을 입력하면 되지만
ex) "find / -perm 0775 또는 775"
어떠한
권한이 포함된(특수권한 같은) 파일을 찾고 싶으시면 "-"를 붙여야 합니다.
ex) "find / -perm -2000"처럼 말이죠.
권한번호는 제가 굳이 쓰지 않아도 되겠죠? 이걸 아직도 못 외웠다면 당신은
권한을 제대로 이해하고 배운 것이 아니라, 그저 따라하기만 했다는 것이죠!
권한이라는 것은 리눅스에서 매우매우매우매우매우 중요하니 꼭 배우고 오십쇼!
권한과 디렉토리 하위까지 권한 적용 :
https://mamu2830.blogspot.com/2019/09/rwx.html
특수권한 :
https://mamu2830.blogspot.com/2019/10/setuid-setgid-sticky-bit.html
-SetUID가 있는 파일들을 찾고 싶다?-
"find / -perm -4000 -ls "
 -권한이 정확히 4750(rwsr-x---)인 파일을 찾고 싶다?-
"find / -perm 4750 -ls"
-권한이 정확히 4750(rwsr-x---)인 파일을 찾고 싶다?-
"find / -perm 4750 -ls"

이런식으로
"-"를 붙일 지, 안 붙일지 생각하시고 사용하시면 되겠습니다
10. find -exec [명령어] {} \;
하.. 드..드디어 거의 끝에 다다랐네요! 지금부터 설명할 것은 제가
시작 부분에 살짝 언급했던 "명령 조건"들 중 하나인
"-exec(execute)" 입니다.
"execute"란 "실행하다"란 의미대로 "뒤에 적은 명령어를 실행하라"는 조건입니다.
그래서 이론상으론
다른 조건들 처럼 "조건 값만 넣은 모습"인
"-exec [명령어(우리가 아는 터미널 명령어)]" 이렇게 사용할 수 있을 것 같지만
실제로 우리가 사용하는
명령어는 보통 단어가 여러개로 이루어져 있잖아요?
그래서 이
"명령 조건"은 특이하게 끝에 "\;"를 넣는데 이건
"명령 조건"에게 "여기까지가 끝이야"를 알려주는 역할입니다.
원래 프로그래밍 언어에서 ;(세미콜론)은 끝이라는 걸 알려주는 역할이기 때문이죠.
그리고
"{}"란 앞서 "실행된 조건들에 의해 검색된 파일들"을 뜻합니다. 무슨소리냐
"find / -name 'abc*' -exec rm -rf {} \;" 이렇게 명령어를 쳤을 때,

위 그림처럼
"앞의 조건에서 검색된 파일들"이 "{}"안에 들어가서
"rm -rf"의 대상 파일이 된 것이죠.
자 그럼 왜
[]가 아니라 "{}"를 쓰며, 또
";"는 왜 \(역슬래쉬, 이스케이프)와 함께 써야하는 지 설명해드리겠습니다!
i) -exec 에서 왜 []를 못 쓰는가
왜 -exec에서 "[]"는 안되고,
"{}"는 되냐면 "2-i) 와일드카드"에서 설명한 것 처럼
"[]"는 문자 단위로 처리를하고, "{}"는 단어 단위로 처리를 하기 때문입니다.
-exec에 "{}"대신 "[]"를 넣었다고 가정해 봅시다.
그러면
앞의 조건들이 발견한 파일 이름들이 "[]"안에 들어간 다음
문자 단위로 나눠질 겁니다. 상상만 해도 끔찍하죠?
그래서 -exec나 -ok와 같은 명령 조건엔 "[]"를 못 씁니다.
또한 이런 질문이 있을 수 있죠.
'왜 -exec의 {}는 따옴표와 함께 쓰이지 않나요?'라고
말이죠.
{}를 따옴표 없이 -exec에서 그냥 쓰는 이유는
"아무것도 안들어있는 {}"는
와일드카드가 아니기에 "find"명령어와 같이 쓰여도,
"find"명령어보다 먼저 처리되지 않기 때문입니다.
그래서
"명령 조건에서의 {}"는
작은 따옴표나 큰 따옴표를 붙이지 않는겁니다.
ii)왜 ";"가 아닌 "\;"인가?
;(세미콜론)이 여기까지가 끝이다라고 알려주는 건 알겠는데,
왜 그냥 ;를 쓰지 않고
\(이스케이프)를 붙여 쓰느냐?
그것은 아까 "2-ii) 쉘의 명령어 처리순서"와 관련이 있습니다.
"2-ii)"에서
쉘은 명령어보다 특수기호, 와일드카드, 변수를 먼저 처리한다고 했었죠?
그래서 ";"가 아닌
"\;"를 쓰는겁니다.
네? 좀 이해가 안된다고요?
다시 말해서
"\;"가 아닌 ";"로 쓰면 "find 명령어의 -exec가 처리하는 ;"가 아닌
"앞의 명령어를 처리했으면 뒤에 명령어를 처리하라는 의미"의 ";"가 된다는 겁니다.
기존의 리눅스 쉘에서의 ;(세미콜론)의 의미는

위 사진처럼
"앞의 명령어를 처리한 뒤, 뒤에 명령어를 처리하란 의미"거든요.
그래서 "
find -exec"에서 그냥 ;(세미콜론)을 쓰면 에러가 나는 겁니다.
그렇기에
\(이스케이프, 기존의 의미에서 빠져 나오겠다)를 ;(세미콜론)에 붙여서
쉘이 먼저 처리하지 않게 하는 겁니다.
이 포스트를 잘 읽으신 분이시라면 또 다른 의문이 드실겁니다
바로 '나 "로 문자를 감싸면, 쉘에서 일반 문자로 취급한다고 했으니 ("는 $, `. \ 제외)
\(이스케이프) 문자 대신 '나 "를 대신 써도 되지 않을까??
라고 말이죠.
크으... 맞아요! 그렇게 해도 됩니다!!

사진에서 \에 묻혀 잘 안보지만. \; 로 할 때의 결과와

이렇게 작은 따옴표, 큰 따옴표로 했을 때와 같은 결과죠?
즉
\; 를 한 이유는 단지,
쉘에서의 ; 로 해석되는 걸 막기 위해서였다~ 입니다.
11) find -ok [명령어] {} \;
"-ok"는 "-exec"와 같은 명령 조건인데
"-exec"와 정말 사용방법이 똑같습니다.
단지 이름
"ok"뜻대로, 찾을 파일에
명령어를 실행할 때마다 확인을 구합니다.
"find / -name 'abcdef*' -ok rm -r {} \;" 이렇게 할 경우
검색된 "abcdef로 시작하는 파일들"을
삭제할 때마다 is ok? is ok? is ok? 물어보는 거죠

이렇게 명령어를 실행할 때마다 물어보는데, "y"나 "yes"를 하지않고
그냥 엔터를 누르면 실행이 안됩니다.
솔직히
삭제 명령어와 같이 위험한 행위를 할 땐, 아무래도 -exec보단
-ok를 쓰는게 더
좋겠죠?
참고로 명령어를 실행할 때,
명령어의 강제 옵션 "-f"를 붙인 경우 형식상
물어보기만 합니다.
그래서 만약
"-ok rm -rf {} \;" 이렇게 한 경우
"y"를 안해도 이미 파일들은
삭제가 된 상태라는 거죠(답장너 상황이랄까...)
이 점만 유의해주시면 될 것 같습니다!
와... 진짜 정말 빨리 끝날 줄 알았던 "find" 명령어 편이 3일이나 걸릴 지는 몰랐네요..
자꾸 예외가 발생해서 그 규칙을 찾느라 구글링하고.. 구글링 해도 안 나와서 결국
저 스스로가 몇 시간동안 연구하며 규칙을 발견하고 ㅠㅠ
힘든 만큼 꼭 도움이 되셨으면 좋겠고!! 오타나 잘못된 정보 발견시 댓글로 꼭 알려주세요~
도움이 되셨다면 따뜻한 댓글 부탁해요 !
정말 큰 힘이 되어 제가 더 퀄리티 좋은 포스트를 쓰게 만듭니다!