










안녕하세요 마무입니다. 이번에 다룰 내용은 "파일시스템이란", "클러스터와 블록차이", "CHS LBA", "추상화 구조란" 입니다.
오늘 이 포스트를 다 읽으시면
지금 리눅스 독학에 포커스를 둔 포스팅을 하고 있고, 이제 "리눅스 마운트, 리눅스 RAID, 리눅스 파일시스템" 등등을 다뤄야하는 데 이 부분을 완벽하게 이해하기 위해선
"운영체제 파일시스템"에 대한 지식이 필요하거든요!
그래서 이렇게 "파일시스템"이란 포스트를 통해 파일시스템을 이해하고 리눅스 포스트로 넘어가도록 하겠습니다!
사실 심화적으로 들어가면 "포렌식" 수준까지 들어갈 정도로
매우 어려워질 수 있기 때문에 핵심적으로만 다루도록 하겠습니다.
-이해에 필요한 개념-
1. 하드디스크 구조 및 원리 :https://mamu2830.blogspot.com/2019/10/blog-post_14.html
2. 리눅스 i-node : https://mamu2830.blogspot.com/2019/07/blog-post.html
--목차--
1. 파일시스템이란, 그리고 파일시스템을 도입한 이유
2. "클러스터, 블록" 탄생 배경
3. 효율적으로 디스크의 데이터를 관리해주는 "파일시스템"
4. 주소 지정 방식(Addressing), "CHS(Cylinder Head Sector)"와 "LBA(Logical Block addressing)"
5. 중간 정리
6. 파일시스템의 추상화 구조(Meta Area, Data Area)
7. 파일시스템의 종류와 역사(FAT, NTFS, EXT 1,2,3,4 XFS)
-------
입니다.
여기서 못 찾은 정보는
운영체제 독학 페이지 : https://mamu2830.blogspot.com/p/blog-page_14.html
리눅스 독학 페이지 : https://mamu2830.blogspot.com/p/blog-page_13.html
에서 찾아보세요!
자 파일시스템.. 컴퓨터쪽으로 공부를 하시는 분들이라면 다들 한 번쯤 들어보셨을 겁니다.
그리고 대부분 "파일시스템"이 뭔지에 대해선 아주 간략하게 아실 겁니다.
파일시스템 : 컴퓨터에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체제
첫 번째 문제는 바로 큰 파일의 데이터들을 읽고 쓰는데 너~~무 느리다는 겁니다. 무슨 소리냐?
데이터를 나눠 기록하는 하나의 섹터들의 크기는 보통 512바이트(0.5KB)라고 했죠?
옛날 컴퓨터가 발전하지 않았을 때는 파일들의 크기들이 그렇게 크지 않아서(뭐 게임 같은 것도, 영상도 없을 때니까요) 0.5KB인 섹터들에 데이터들을 나눠 담고, 또 다시
불러와 사용하는 데 큰 문제가 없었습니다.
예를 들어, 크기가 10MB인 파일을 사용한다 치면 디스크에서 메모리로 2*1024*10개의 섹터만 불러오면 되는 거니깐요~(어라?)
그런데 컴퓨터 기술이 발전함에 따라, 컴퓨터에서 사용하는 파일의 크기도 비약적으로
커지기 시작해지죠. 지금 저희들이 하는 게임만 해도 요즘 용량이 최소 몇 기가에서 몇 십 기가 심지어는 몇 백 기가가 되잖아요?
그래서 0.5KB 크기의 섹터 단위로 몇 십기가의 데이터를 읽고 저장하기엔 너~~~~~~무
오래걸리고 답답해 미치는 겁니다. 10GB를 섹터의 수로 따지면 2*1024*1024*10개...
컴퓨터의 기술력은 바로 "속도" 잖아요? 아무리 인터넷이 빨라졌다고 쳐도 디스크에서
데이터를 이렇게 "섹터"단위로 읽고 저장해서 오래걸리면 의미가 없는 것이죠.
그래서 이것을 해결하기 위해, 도입된 기술이 바로
"섹터들을 한 번에 여러 개를 읽는 것" 입니다.
섹터(512바이트)씩 파일의 정보를 나눠 저장하고 읽어 들이기 보단, 2개(1KB)씩, 4개(2KB)씩, 8개(4KB)씩 묶어서 읽고(사용하고) 저장하는 것이죠.
예를 들어 102박스를 어떤 곳으로 옮기는데, 1개씩 옮기는 거랑 4개씩 옮기는 것 중
어느것이 더 빠르겠습니까~ 바로 답이 나오죠?
그래서 이렇게 섹터들을 묶은 단위를 "클러스터(Cluster)" 또는 "블록(Block)" 이라고 합니다.
물론 이렇게 여러개를 한번에 옮기면 마지막엔 2개만 옮기면 되는데, 4개씩 옮기기 때문에 추가로 2개의 빈 박스가 더 옮겨질텐데요
이렇듯 "블록(클러스터)" 단위로 사용하다보면 의미 없는 공간이 추가로 낭비되는 현상이 생기는데 이걸 "슬랙 공간(Slack space)"이라고 합니다. 이 "슬랙"이라는 개념은 포렌식쪽으로 준비하는 사람들이 공부하는 영역으로 저희가 배우기엔 좀 어렵습니다.
그러니 "슬랙(Slack)"이란 게 있구나~ 하고 넘어갑시다
운영체제쪽을 공부하다보면 어떤 분은 "클러스터"라 하고, 어떤 분들은 "블록"이라고 해서 공부하는 입장에선 상당히 헷갈릴 수 있는데 둘의 차이는 없습니다. 그냥 "클러스터"는 윈도우 운영체제에서 자주 사용하는 용어고 "블록"은 유닉스 계열 운영체제에서 자주 사용하는 용어라고 생각하시면 됩니다.
또한 블록(클러스터)를 몇 개의 섹터로 계산하는 지는 파일시스템마다 다릅니다.
하지만 여기서 생각해야 하는 것이 실제로 디스크는 섹터들로 나뉘어져 있고, 물리적으로 "클러스터" 또는 "블록"이란 것은 없잖아요? 그래서 블록이란 것을 "파일시스템"이 소프트웨어적으로 계산해줘서 운영체제가 사용할 수 있는 겁니다.
즉 "클러스터, 블록"이란 단위를 계산해주는 것도 결국 파일시스템의 역할 중 하나라는 겁니다.
그래서 "파일시스템" 덕분에 "운영체제"는 블록(클러스터) 단위로 데이터를 사용 할 수 있는 것이고 또 사용하기 때문에, "운영체제"에서 나오는 용어들 "FCB(File Control Block)"나 "부트 제어 블록" 등에 "블록"이 들어가는 겁니다.
물론 "운영체제"에 "파일시스템"이 포함되는 거지만, 엄연히 따지면 그렇다는 것이죠~
기존 실린더 방식 데이터 보관의 두 번째 문제는, 디스크에 데이터를 실제로 저장하고 사용할 때 능률이 매우 떨어진다. 입니다.
기존엔 데이터를 디스크의 실린더 순으로 저장한다는거 기억나시죠?
만약 현대의 큰 파일들의 데이터도 그렇게 저장하고, 삭제한다면 어떻게 될까요?
예로들어 하나의 플래터만 있다고 가정하고, 그곳에 데이터를 저장한다고 쳐 봅시다.

같은 파일의 데이터들은 같은 색깔이라 치겠습니다. 플래터가 하나니까 그림처럼 트랙순으로만 데이터가 저장되겠고, 그림처럼 데이터들이 저장돼 있다 쳐보겠습니다.
여기까지만 보면 문제가 없어보이지만 이제 디스크에 있는 파일들을 실제로 사용한다고 생각하면 여러 문제에 봉착합니다. 가장 먼저 봉착할 문제는 바로
섹터에 저장된 기존 파일의 크기가 더 커지면 어떻게 할 것인가?
입니다.
자, 윗 그림의 3개의 빨간색 섹터가 보이시죠? 원래는 3개의 섹터 크기의 파일이였는데 이 파일을 수정해서 크기가 커져 섹터가 4개가 크기가 됐다면, 늘어난 1개 크기의 데이터는 어디에 저장할까요?(근처는 다른 파일들의 데이터로 꽉 차있어 넣을 수가 없습니다.)
자 그럼 어쩔 수 없이 다른 트랙의 섹터에 정보를 넣어야겠죠?

이렇게 다른 트랙에 데이터를 넣었습니다. 자 섹터에 데이터를 저장하는 건 괜찮다 쳐요.
하지만 빨간 섹터 파일을 사용할 땐 컴퓨터가 다른 트랙에 저장된 빨간 섹터가 어디에 있는지 어떻게 알까요? 우리야 색깔을 표시해서 아는 거지, 컴퓨터는 모른다는 겁니다.
결국 컴퓨터는 따로 저장된 그 빨간색 섹터 1개를 찾기위해 자원을(시간을) 엄청 투자 할 겁니다. 즉, 능률이 떨어지는 것이죠.
자 그럼 반대로
기존의 파일 크기가 줄어들거나, 지워졌을 때 생기는 공간은 어떻게 하나?
란 문제가 또 있습니다.


사진처럼 빈 공간이 트랙 중간 중간 생길겁니다. 결국 파일을 사용하면 사용할수록 저렇게 빈 섹터가 생기며 점점 더 공간이 낭비될 겁니다. 그렇다고 저 빈 공간을 낭비하기 싫어서
저기에 다른 파일을 만약 넣었다 쳐도, 또 용량이 늘어난다면...오우....뭐 생각만 해도 골치가 아픕니다.
그러면 누군가는 말하겠죠. '아니!!! 그럼 저 섹터들을 모아서 여분의 공간을 없에면 되잖아요!!!! 바보셈!!?' 이라고요. 그렇죠.. 바로 그겁니다. 그게 바로 세 번째 문제예요.
3. 디스크 모음을 어떻게 할 것인가.
그래요 저 여분의 공간들은, 연관된 섹터들을 다시 한 곳으로 모아서 없에면 되는 일이지요. 그런데 그걸 어떻게 하죠? 뭐가 관련된 파일인지 디스크는 모르는데 말이죠..
그래서! 지금까지 설명한 모든 문제를 해결하기 위해 바로 "파일 시스템"이란 것이 도입이 된 겁니다!
그럼 이제 파일시스템이 하는 역할이 어느정도 이해가 되실테지만 다시 한번 정리해볼게요.
1. 데이터를 더 빠르게 읽고 저장할 수 있는 단위 블록(클러스터)을 소프트웨어적으로 계산해준다.
2. 분산 저장된 연관된 데이터들을 빠르게 찾게 해준다.
3. 디스크 조각(섹터)모음과 같이 디스크 공간을 효율적으로 사용하게 해준다.
그렇습니다. 파일시스템이 하는 역할을 크게, 바로 위에 말한 세 가지 입니다.
이제 저 "세 가지"를 각각 어떤 방식으로 하냐에 따라서 파일시스템의 종류가 달라지게 되는 겁니다.
그런데 여기서 또 의문이 들지 않습니까? 일단 제일 먼저, 여러 개를 한 번에 읽는 단위인
'블록'을 "파일시스템"이 구현해주는 건 알겠는데 어떤 원리로 하는거지?'
라고요.

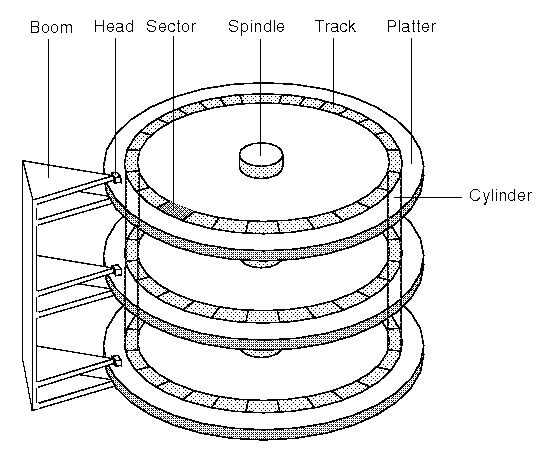
다시 말해서, 사진처럼 우리가 아는 하드디스크는 원통 모양에 섹터, 트랙, 실린더의
"3차원 구조"인데 어떻게 "블록"을 계산하냐죠.
그 의문을 해결하기 위해선 바로 "주소 지정 방식(Addressing)"을 알고 가야합니다.
네 "파일시스템"이 알아서 블록계산을 해준다고 해도 디스크는 3차원적 구조이기
때문에, 분명 각각 디스크의 섹터에 주소나 어떤 규칙같은 게 없으면 "파일시스템"이
블록(클러스터)계산을 할 수가 없을 겁니다.
그래서 당연하게도 섹터에 주소 지정를 하는 방식이 있는데, 제일 먼저 나온 주소 지정방식이 바로 "CHS(Cylinder-Head-Sector)"방식입니다. 말 그대로 "Cylinder-Head-Sector"순으로 주소를 지정한다는 뜻으로, 실린더와 헤드는 0번부터 시작하며, 섹터는 1번부터 시작을 합니다.
실린더는 맨 바깥쪽부터 0번이고
헤드는 맨 밑에서부터 0번
섹터는 1번부터 시작해 반 시계 방향으로 번호가 증가합니다.



어휴... 나름 처음 공부하시는 분들은 정말 머리가 핑~ 돌 정도로 많은 정보를 알려드렸는데
좀 순서가 뒤죽박죽이라 힘드실테니, 다시 한번 순서대로 중간 정리를 해드릴게요.
4. 이제 이 "BIOS"가 구현한 "LBA"를 이용해 "파일시스템"이 본격적으로 데이터를 효율적이게 관리를 하고 사용할 수 있게 블록(클러스터)를 계산해주는 것이다.

"FAT" 뒤에 붙은 숫자는 클러스터를 만들 수 있는 "비트의 수" 입니다.
예를 들어, "1 비트"는 "on과 off"로 총 2개 경우의 수가 있고, 2비트는 2의 2승으로 4의 경우의 수가 있고 4비트는 2의 4승으로 16개 경우의 수가 있죠?
같은 원리로 FAT12는 2의 12승의 수 만큼 클러스터(블록)을 가질 수 있다는 뜻이고
FAT32는 2의 32승의 수 만큼 클러스터를 가질 수 있다는 뜻입니다.(물론 자세하게 따지면 또 추가로 몇 개를 더 빼고 계산해야 합니다.)
수가 높을 수록 클러스터를 많이 가질 수 있으니 그 만큼 사용할 수 있는
용량이 더 커지겠죠?
"FAT 32"는 또 기가막히게 외우기 쉽게, 지원하는 "최대 드라이브 크기는 32GB"이고 한 파일당 4GB를 지원합니다. 그래서 USB에 자주 쓰이죠 하지만 한 파일에 4GB밖에 지원을 안하기에, 4GB 이상 크기 파일을 USB에 옮기려 하면 못 옮기고 파일시스템을 바꿔야한다는 설정이 나오는 겁니다.
"FAT" 파일시스템의 구조는

"FAT Area"는 제가 위에서 언급한 "Meta Area"라고 생각하시면 됩니다.
"Data Area"는 말 그대로 데이터 지역으로, 우리가 흔히 사용하는 파일들 데이터들이
저장되는 공간입니다.
사실 여기까지만 알고나면 똥 싸고 덜 닦은 기분이 드실텐데...
더욱 자세히 설명하기 시작하면 이 포스트가 언제 끝날지 모르겠고 ㅠㅠ
또 너무 리눅스 공부를 위한 취지를 벗어난 부분이기 때문에 훗날 파일시스템 심화적인 내용을 다루게 된다면 그 때 다루도록 하겠습니다.
윈도우 운영체제에 사용되는 파일 시스템
NTFS(New Technology File System)
원래 "저널(journal)"이란 뜻대로 "저널링 기술"은, 항상 디스크에 정보를 변경하기 전에 변경사항들을 "저널"이라고 부르는 로그공간에 미리 기록을 해두는 겁니다. 뭐 어디에 무엇을 저장을 했다 이런 기록을 말이죠.
그래서 "기록(로그)"을 남겨뒀기 때문에 디스크에 정보를 저장하던 중 전원이 끊기거나 문제가 발생했어도 "저널 로그"를 보고 다시 복구할 수 있는 겁니다.
뭐 예시를 들자면 쇼핑하기 전에 구매할 리스트를 미리 적어놓고 가지고 가면, 마트에 도착했을 때 갑자기 뭘 사야할 지 기억이 안나도 리스트를 보고 제대로 살 수 있는 것과 마찬가지인 것이죠.
1993년 실리콘 그래픽스가 만든 64비트 저널링 파일시스템이며
하.. 이번 포스트는 진짜 5일동안 했네요.. 원래 제 성격이 모르는 거 하나 있으면 그냥 넘어가질 못해서... 이렇게 길게 포스트를 하게 된 것 같습니다..!
아 그리고 인후두염에 걸려서ㅠㅠ 3일간 포스트를 못해서 더 늦게 한 것도 있슴다 ㅠㅠ
여러분들 건강 잘 챙기세요... 진짜 아픈 뒤에야 건강이 얼마나 소중한지 깨닫는 것 같아요~
블로그 포스트 좋아요, 팔로우는 매우 큰 도움이 되며!! 네이버 블로그 공감클릭도 큰 도움이 됩니당!! 그럼 힘들게 디스크, 파일시스템에서 이해했으니 이제 본격적으로
"리눅스 파일시스템"과 마운트, RAID에 대해서 포스트 하도록 하겠습니다~
오늘 이 포스트를 다 읽으시면
파일시스템이란, 클러스터와 블록 차이, CHS LBA, 추상화구조, 리눅스 파일시스템 종류
에 대해서 확실하게 아시게 될겁니다!지금 리눅스 독학에 포커스를 둔 포스팅을 하고 있고, 이제 "리눅스 마운트, 리눅스 RAID, 리눅스 파일시스템" 등등을 다뤄야하는 데 이 부분을 완벽하게 이해하기 위해선
"운영체제 파일시스템"에 대한 지식이 필요하거든요!
그래서 이렇게 "파일시스템"이란 포스트를 통해 파일시스템을 이해하고 리눅스 포스트로 넘어가도록 하겠습니다!
사실 심화적으로 들어가면 "포렌식" 수준까지 들어갈 정도로
매우 어려워질 수 있기 때문에 핵심적으로만 다루도록 하겠습니다.
-이해에 필요한 개념-
1. 하드디스크 구조 및 원리 :https://mamu2830.blogspot.com/2019/10/blog-post_14.html
2. 리눅스 i-node : https://mamu2830.blogspot.com/2019/07/blog-post.html
--목차--
1. 파일시스템이란, 그리고 파일시스템을 도입한 이유
2. "클러스터, 블록" 탄생 배경
3. 효율적으로 디스크의 데이터를 관리해주는 "파일시스템"
4. 주소 지정 방식(Addressing), "CHS(Cylinder Head Sector)"와 "LBA(Logical Block addressing)"
5. 중간 정리
6. 파일시스템의 추상화 구조(Meta Area, Data Area)
7. 파일시스템의 종류와 역사(FAT, NTFS, EXT 1,2,3,4 XFS)
-------
입니다.
여기서 못 찾은 정보는
운영체제 독학 페이지 : https://mamu2830.blogspot.com/p/blog-page_14.html
리눅스 독학 페이지 : https://mamu2830.blogspot.com/p/blog-page_13.html
에서 찾아보세요!
1. 파일시스템이란?
자 파일시스템.. 컴퓨터쪽으로 공부를 하시는 분들이라면 다들 한 번쯤 들어보셨을 겁니다.
그리고 대부분 "파일시스템"이 뭔지에 대해선 아주 간략하게 아실 겁니다.
파일시스템 : 컴퓨터에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체제
라고 말이죠.
음 그런데 이렇게 "파일이나 자료를 쉽게 발견 및 접근할 수 있도록"라고만 보면
"소프트웨어"적으로만 관련 있는 프로그램이라 생각하게 되는데, "파일시스템"은 사실 "소프트웨어"뿐만 아니라 "하드웨어"적으로도 밀접하게 관련있는 프로그램입니다.
무슨 소리인지 아직은 이해가 잘 안되실 텐데
이럴 땐 "파일시스템"이란 것이 왜 생겼는 지를 알고나면 이해가 되실 겁니다.
"하드 디스크 구조와 원리" 포스트에서 "섹터(Sector), 트랙(Track), 실린더(Cylinder)" 개념을 언급하면서, 디스크에 기본적으로 데이터를 기록하는 순서와 원리를 설명했었는데
기억이 나시나요?

"소프트웨어"적으로만 관련 있는 프로그램이라 생각하게 되는데, "파일시스템"은 사실 "소프트웨어"뿐만 아니라 "하드웨어"적으로도 밀접하게 관련있는 프로그램입니다.
무슨 소리인지 아직은 이해가 잘 안되실 텐데
이럴 땐 "파일시스템"이란 것이 왜 생겼는 지를 알고나면 이해가 되실 겁니다.
"하드 디스크 구조와 원리" 포스트에서 "섹터(Sector), 트랙(Track), 실린더(Cylinder)" 개념을 언급하면서, 디스크에 기본적으로 데이터를 기록하는 순서와 원리를 설명했었는데
기억이 나시나요?

결국 이렇게 실린더(Cylinder) 순서로 데이터를 각 하드디스크 최소단위인 섹터(Sector)에
저장한다 고 말이죠.
자 여기까지 보면 이론상으론 완벽하게 보일 수 있습니다. 하지만 현재 우리가 사용하는 "파일들 크기"를 이 이론에 적용하면 문제가 생깁니다.
그래서 밑에 설명할 문제들을 해결하기 위해 "파일시스템"이란 게 생긴 겁니다.
저장한다 고 말이죠.
자 여기까지 보면 이론상으론 완벽하게 보일 수 있습니다. 하지만 현재 우리가 사용하는 "파일들 크기"를 이 이론에 적용하면 문제가 생깁니다.
그래서 밑에 설명할 문제들을 해결하기 위해 "파일시스템"이란 게 생긴 겁니다.
2. 클러스터, 블록 등장 배경
첫 번째 문제는 바로 큰 파일의 데이터들을 읽고 쓰는데 너~~무 느리다는 겁니다. 무슨 소리냐?
데이터를 나눠 기록하는 하나의 섹터들의 크기는 보통 512바이트(0.5KB)라고 했죠?
옛날 컴퓨터가 발전하지 않았을 때는 파일들의 크기들이 그렇게 크지 않아서(뭐 게임 같은 것도, 영상도 없을 때니까요) 0.5KB인 섹터들에 데이터들을 나눠 담고, 또 다시
불러와 사용하는 데 큰 문제가 없었습니다.
예를 들어, 크기가 10MB인 파일을 사용한다 치면 디스크에서 메모리로 2*1024*10개의 섹터만 불러오면 되는 거니깐요~(어라?)
그런데 컴퓨터 기술이 발전함에 따라, 컴퓨터에서 사용하는 파일의 크기도 비약적으로
커지기 시작해지죠. 지금 저희들이 하는 게임만 해도 요즘 용량이 최소 몇 기가에서 몇 십 기가 심지어는 몇 백 기가가 되잖아요?
그래서 0.5KB 크기의 섹터 단위로 몇 십기가의 데이터를 읽고 저장하기엔 너~~~~~~무
오래걸리고 답답해 미치는 겁니다. 10GB를 섹터의 수로 따지면 2*1024*1024*10개...
컴퓨터의 기술력은 바로 "속도" 잖아요? 아무리 인터넷이 빨라졌다고 쳐도 디스크에서
데이터를 이렇게 "섹터"단위로 읽고 저장해서 오래걸리면 의미가 없는 것이죠.
그래서 이것을 해결하기 위해, 도입된 기술이 바로
"섹터들을 한 번에 여러 개를 읽는 것" 입니다.
섹터(512바이트)씩 파일의 정보를 나눠 저장하고 읽어 들이기 보단, 2개(1KB)씩, 4개(2KB)씩, 8개(4KB)씩 묶어서 읽고(사용하고) 저장하는 것이죠.
예를 들어 102박스를 어떤 곳으로 옮기는데, 1개씩 옮기는 거랑 4개씩 옮기는 것 중
어느것이 더 빠르겠습니까~ 바로 답이 나오죠?
그래서 이렇게 섹터들을 묶은 단위를 "클러스터(Cluster)" 또는 "블록(Block)" 이라고 합니다.
물론 이렇게 여러개를 한번에 옮기면 마지막엔 2개만 옮기면 되는데, 4개씩 옮기기 때문에 추가로 2개의 빈 박스가 더 옮겨질텐데요
이렇듯 "블록(클러스터)" 단위로 사용하다보면 의미 없는 공간이 추가로 낭비되는 현상이 생기는데 이걸 "슬랙 공간(Slack space)"이라고 합니다. 이 "슬랙"이라는 개념은 포렌식쪽으로 준비하는 사람들이 공부하는 영역으로 저희가 배우기엔 좀 어렵습니다.
그러니 "슬랙(Slack)"이란 게 있구나~ 하고 넘어갑시다
운영체제쪽을 공부하다보면 어떤 분은 "클러스터"라 하고, 어떤 분들은 "블록"이라고 해서 공부하는 입장에선 상당히 헷갈릴 수 있는데 둘의 차이는 없습니다. 그냥 "클러스터"는 윈도우 운영체제에서 자주 사용하는 용어고 "블록"은 유닉스 계열 운영체제에서 자주 사용하는 용어라고 생각하시면 됩니다.
또한 블록(클러스터)를 몇 개의 섹터로 계산하는 지는 파일시스템마다 다릅니다.
하지만 여기서 생각해야 하는 것이 실제로 디스크는 섹터들로 나뉘어져 있고, 물리적으로 "클러스터" 또는 "블록"이란 것은 없잖아요? 그래서 블록이란 것을 "파일시스템"이 소프트웨어적으로 계산해줘서 운영체제가 사용할 수 있는 겁니다.
즉 "클러스터, 블록"이란 단위를 계산해주는 것도 결국 파일시스템의 역할 중 하나라는 겁니다.
그래서 "파일시스템" 덕분에 "운영체제"는 블록(클러스터) 단위로 데이터를 사용 할 수 있는 것이고 또 사용하기 때문에, "운영체제"에서 나오는 용어들 "FCB(File Control Block)"나 "부트 제어 블록" 등에 "블록"이 들어가는 겁니다.
물론 "운영체제"에 "파일시스템"이 포함되는 거지만, 엄연히 따지면 그렇다는 것이죠~
3. 효율적으로 디스크에 데이터를 관리해주는 "파일시스템"
기존 실린더 방식 데이터 보관의 두 번째 문제는, 디스크에 데이터를 실제로 저장하고 사용할 때 능률이 매우 떨어진다. 입니다.
기존엔 데이터를 디스크의 실린더 순으로 저장한다는거 기억나시죠?
만약 현대의 큰 파일들의 데이터도 그렇게 저장하고, 삭제한다면 어떻게 될까요?
예로들어 하나의 플래터만 있다고 가정하고, 그곳에 데이터를 저장한다고 쳐 봅시다.

같은 파일의 데이터들은 같은 색깔이라 치겠습니다. 플래터가 하나니까 그림처럼 트랙순으로만 데이터가 저장되겠고, 그림처럼 데이터들이 저장돼 있다 쳐보겠습니다.
여기까지만 보면 문제가 없어보이지만 이제 디스크에 있는 파일들을 실제로 사용한다고 생각하면 여러 문제에 봉착합니다. 가장 먼저 봉착할 문제는 바로
섹터에 저장된 기존 파일의 크기가 더 커지면 어떻게 할 것인가?
입니다.
자, 윗 그림의 3개의 빨간색 섹터가 보이시죠? 원래는 3개의 섹터 크기의 파일이였는데 이 파일을 수정해서 크기가 커져 섹터가 4개가 크기가 됐다면, 늘어난 1개 크기의 데이터는 어디에 저장할까요?(근처는 다른 파일들의 데이터로 꽉 차있어 넣을 수가 없습니다.)
자 그럼 어쩔 수 없이 다른 트랙의 섹터에 정보를 넣어야겠죠?

이렇게 다른 트랙에 데이터를 넣었습니다. 자 섹터에 데이터를 저장하는 건 괜찮다 쳐요.
하지만 빨간 섹터 파일을 사용할 땐 컴퓨터가 다른 트랙에 저장된 빨간 섹터가 어디에 있는지 어떻게 알까요? 우리야 색깔을 표시해서 아는 거지, 컴퓨터는 모른다는 겁니다.
결국 컴퓨터는 따로 저장된 그 빨간색 섹터 1개를 찾기위해 자원을(시간을) 엄청 투자 할 겁니다. 즉, 능률이 떨어지는 것이죠.
자 그럼 반대로
기존의 파일 크기가 줄어들거나, 지워졌을 때 생기는 공간은 어떻게 하나?
란 문제가 또 있습니다.

이렇게 기존에 파일들이 저장돼 있다가, 파일이 수정을 통해 크기가 줄었거나, 삭제
됐다고 쳐봅시다.
그 예시로 "노란색 파일의 크기가 줄어들고" , "파란색 파일을 지웠다"고 쳐보죠 그러면
어떻게 될까요?
됐다고 쳐봅시다.
그 예시로 "노란색 파일의 크기가 줄어들고" , "파란색 파일을 지웠다"고 쳐보죠 그러면
어떻게 될까요?

사진처럼 빈 공간이 트랙 중간 중간 생길겁니다. 결국 파일을 사용하면 사용할수록 저렇게 빈 섹터가 생기며 점점 더 공간이 낭비될 겁니다. 그렇다고 저 빈 공간을 낭비하기 싫어서
저기에 다른 파일을 만약 넣었다 쳐도, 또 용량이 늘어난다면...오우....뭐 생각만 해도 골치가 아픕니다.
그러면 누군가는 말하겠죠. '아니!!! 그럼 저 섹터들을 모아서 여분의 공간을 없에면 되잖아요!!!! 바보셈!!?' 이라고요. 그렇죠.. 바로 그겁니다. 그게 바로 세 번째 문제예요.
3. 디스크 모음을 어떻게 할 것인가.
그래요 저 여분의 공간들은, 연관된 섹터들을 다시 한 곳으로 모아서 없에면 되는 일이지요. 그런데 그걸 어떻게 하죠? 뭐가 관련된 파일인지 디스크는 모르는데 말이죠..
그래서! 지금까지 설명한 모든 문제를 해결하기 위해 바로 "파일 시스템"이란 것이 도입이 된 겁니다!
그럼 이제 파일시스템이 하는 역할이 어느정도 이해가 되실테지만 다시 한번 정리해볼게요.
1. 데이터를 더 빠르게 읽고 저장할 수 있는 단위 블록(클러스터)을 소프트웨어적으로 계산해준다.
2. 분산 저장된 연관된 데이터들을 빠르게 찾게 해준다.
3. 디스크 조각(섹터)모음과 같이 디스크 공간을 효율적으로 사용하게 해준다.
그렇습니다. 파일시스템이 하는 역할을 크게, 바로 위에 말한 세 가지 입니다.
이제 저 "세 가지"를 각각 어떤 방식으로 하냐에 따라서 파일시스템의 종류가 달라지게 되는 겁니다.
그런데 여기서 또 의문이 들지 않습니까? 일단 제일 먼저, 여러 개를 한 번에 읽는 단위인
'블록'을 "파일시스템"이 구현해주는 건 알겠는데 어떤 원리로 하는거지?'
라고요.

다시 말해서, 사진처럼 우리가 아는 하드디스크는 원통 모양에 섹터, 트랙, 실린더의
"3차원 구조"인데 어떻게 "블록"을 계산하냐죠.
그 의문을 해결하기 위해선 바로 "주소 지정 방식(Addressing)"을 알고 가야합니다.
4. 주소 지정 방식(Addressing)의 CHS(Cylinder Head Sector), LBA(Logical Block addressing)
네 "파일시스템"이 알아서 블록계산을 해준다고 해도 디스크는 3차원적 구조이기
때문에, 분명 각각 디스크의 섹터에 주소나 어떤 규칙같은 게 없으면 "파일시스템"이
블록(클러스터)계산을 할 수가 없을 겁니다.
그래서 당연하게도 섹터에 주소 지정를 하는 방식이 있는데, 제일 먼저 나온 주소 지정방식이 바로 "CHS(Cylinder-Head-Sector)"방식입니다. 말 그대로 "Cylinder-Head-Sector"순으로 주소를 지정한다는 뜻으로, 실린더와 헤드는 0번부터 시작하며, 섹터는 1번부터 시작을 합니다.
실린더는 맨 바깥쪽부터 0번이고
헤드는 맨 밑에서부터 0번
섹터는 1번부터 시작해 반 시계 방향으로 번호가 증가합니다.
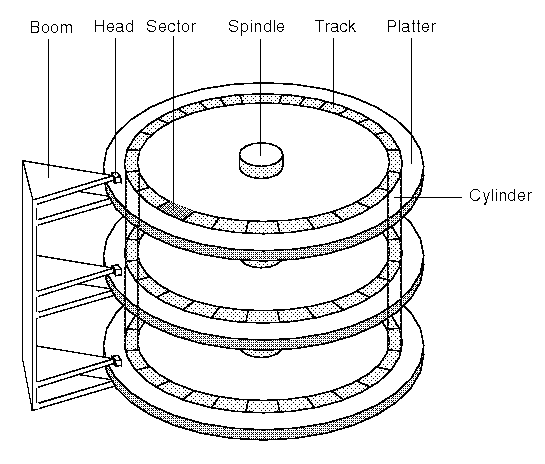
사진 출처(https://www.datarecoverytools.co.uk/2009/12/22/chs-lba-addressing-and-their-conversion-algorithms/)
이 사진을 보시면서 이해를 해봅시다. 예로들어 CHS방식에서 (2,3,2)라고 한다면
2번째 실린더의
이 사진을 보시면서 이해를 해봅시다. 예로들어 CHS방식에서 (2,3,2)라고 한다면
2번째 실린더의

3번 헤드의

2번 섹터 ('파란색 표시' 보이시나요?)

이런식으로 되는 것이죠.
그래서 만약에 한 파일의 시작 데이터 위치가 (2,3,2)라고 하면 저기서부터 반시계 방향으로 섹터를 읽는 겁니다.
이처럼 "CHS(Cylinder-head-sector)" 방식은 실제 물리적인 디스크 위치를 고려한
"물리적 주소 지정 방식"입니다.
하지만 이 지정 방식의 가장 큰 단점은, 플래터 중앙으로 갈 수록 물리적으로
한 트랙 내 섹터의 수는 외부쪽에 비해서 적어지기 때문에(둘레가 점점 작아지니 그 만큼 들어갈 섹터의 수도 당연히 적어지겠죠?)
디스크 주소지정에서의 혼돈을 막기 위해, 수가 적은 내부쪽 섹터의 수로 통일해서 "CHS"를 계산하게 됐고 그래서 실제 섹터 수보다 적게 사용할 수 밖에 없는 겁니다.
즉, 실제 디스크 용량보다 더 적게 사용할 수 밖에 없는 것이죠.
그리고 심지어 과학 기술이 발전함에 따라 한 "플래터"내 집적도가 높아져서(한 플래터에 많은 섹터를 넣으므로)플래터의 외부와 내부의 섹터 수 차이는 더욱 심해집니다.
그래서 이런 문제를 해결하기 위해 나온 주소 지정 방식이 바로!
"LBA(Logical Block Addressing)"입니다. 말 그대로 "논리적"으로 주소를 계산하는 것인데
무슨 소리냐면, 원래 "CHS(Cylinder-head-sector)"는 (0,0,1) (0,0,2), (0,0,3)..이렇게 3차원적으로 주소를 지정했다면, "LBA(Logical Block Addressing)"은 논리적이게 모든 디스크의 섹터를 한 줄로 구현해서 실제 위치에 상관 없이 모든 섹터를 순서대로 주소를 지정해 계산하는 겁니다.
예를 들어서, "CHS"방식은 (0,0,1), (0,0,2), (0,0,3)....(0,1,1) 이고 이걸
"LBA"방식으로 바꾸면 0, 1, 2..........100, 101, 102 이렇게 주소를 지정하는 것이죠.
이렇게 3차원적이고 물리적인 위치의 디스크 섹터들을 "한 줄로 있다"고 "논리적"으로 생각하고 주소를 지정하면, 모든 디스크의 섹터들에 주소를 할당하고 사용할 수 있죠?
네 글로만 보면 이해가 안 될테니 바로 밑에 사진을 보면 이해가 되실 겁니다.

위에서 말한 "LBA"방식으로 주소를 지정한 것을 그림으로 표현한다면, 이런식으로 표현이 될 겁니다. 딱 보기에도 훨씬 깔끔하고 편하죠? 어? 그런데 어디서 많이 본 그림 아닙니까?
그렇죠 대부분 디스크나 메모리에서 공간을 표시할 때 이런식으로 한 줄로 표시를 하죠?
물론 메모리에선 보통 '세로'로 세우긴 하지만요 ㅎㅎ
이렇듯 "LBA(Logical Block Addressing)" 주소 지정 방식은 지금까지도 사용되는 주소 지정 방식입니다. 그리고 이름대로 "논리적 주소 지정 방식"이라고 합니다.
그런데 이 "LBA" 구현은 누가 해줄까요?
누가 "실제 디스크 섹터 위치 <---> 논리적 섹터 위치" 이렇게 바꿔주느냐는 것이죠.
그것은 바로 "BIOS(Basic Input/Output system)"가 해줍니다.
'여기서 BIOS는 또 뭐야!?' 할 수 있는데... 음... 일단 이것도 자세히 설명하라 하면 너무
길어지기 때문에 그냥
"Basic(직접적으로) Input/Output(하드웨어의 입출력을 제어하는) System(소프트웨어)"
라고 알아두세요. 기존 컴퓨터의 하드웨어와 소프트웨어 상호작용은 이 "BIOS"를 통해서 가능한 것입니다.
즉, 하드웨어 <---> BIOS <---> 소프트웨어(운영체제)
어쨌든 이렇게 "BIOS"에 의해 논리적으로 디스크의 공간이 한 줄인양 주소가 할당이 된 뒤
이제 이 주소에 정보들을 어디에 저장하고, 어떻게 사용할지 등 본격적인 관리를
"파일시스템"이 해주는 것 입니다.
그래서 만약에 한 파일의 시작 데이터 위치가 (2,3,2)라고 하면 저기서부터 반시계 방향으로 섹터를 읽는 겁니다.
이처럼 "CHS(Cylinder-head-sector)" 방식은 실제 물리적인 디스크 위치를 고려한
"물리적 주소 지정 방식"입니다.
하지만 이 지정 방식의 가장 큰 단점은, 플래터 중앙으로 갈 수록 물리적으로
한 트랙 내 섹터의 수는 외부쪽에 비해서 적어지기 때문에(둘레가 점점 작아지니 그 만큼 들어갈 섹터의 수도 당연히 적어지겠죠?)
디스크 주소지정에서의 혼돈을 막기 위해, 수가 적은 내부쪽 섹터의 수로 통일해서 "CHS"를 계산하게 됐고 그래서 실제 섹터 수보다 적게 사용할 수 밖에 없는 겁니다.
즉, 실제 디스크 용량보다 더 적게 사용할 수 밖에 없는 것이죠.
그리고 심지어 과학 기술이 발전함에 따라 한 "플래터"내 집적도가 높아져서(한 플래터에 많은 섹터를 넣으므로)플래터의 외부와 내부의 섹터 수 차이는 더욱 심해집니다.
그래서 이런 문제를 해결하기 위해 나온 주소 지정 방식이 바로!
"LBA(Logical Block Addressing)"입니다. 말 그대로 "논리적"으로 주소를 계산하는 것인데
무슨 소리냐면, 원래 "CHS(Cylinder-head-sector)"는 (0,0,1) (0,0,2), (0,0,3)..이렇게 3차원적으로 주소를 지정했다면, "LBA(Logical Block Addressing)"은 논리적이게 모든 디스크의 섹터를 한 줄로 구현해서 실제 위치에 상관 없이 모든 섹터를 순서대로 주소를 지정해 계산하는 겁니다.
예를 들어서, "CHS"방식은 (0,0,1), (0,0,2), (0,0,3)....(0,1,1) 이고 이걸
"LBA"방식으로 바꾸면 0, 1, 2..........100, 101, 102 이렇게 주소를 지정하는 것이죠.
이렇게 3차원적이고 물리적인 위치의 디스크 섹터들을 "한 줄로 있다"고 "논리적"으로 생각하고 주소를 지정하면, 모든 디스크의 섹터들에 주소를 할당하고 사용할 수 있죠?
네 글로만 보면 이해가 안 될테니 바로 밑에 사진을 보면 이해가 되실 겁니다.

위에서 말한 "LBA"방식으로 주소를 지정한 것을 그림으로 표현한다면, 이런식으로 표현이 될 겁니다. 딱 보기에도 훨씬 깔끔하고 편하죠? 어? 그런데 어디서 많이 본 그림 아닙니까?
그렇죠 대부분 디스크나 메모리에서 공간을 표시할 때 이런식으로 한 줄로 표시를 하죠?
물론 메모리에선 보통 '세로'로 세우긴 하지만요 ㅎㅎ
이렇듯 "LBA(Logical Block Addressing)" 주소 지정 방식은 지금까지도 사용되는 주소 지정 방식입니다. 그리고 이름대로 "논리적 주소 지정 방식"이라고 합니다.
그런데 이 "LBA" 구현은 누가 해줄까요?
누가 "실제 디스크 섹터 위치 <---> 논리적 섹터 위치" 이렇게 바꿔주느냐는 것이죠.
그것은 바로 "BIOS(Basic Input/Output system)"가 해줍니다.
'여기서 BIOS는 또 뭐야!?' 할 수 있는데... 음... 일단 이것도 자세히 설명하라 하면 너무
길어지기 때문에 그냥
"Basic(직접적으로) Input/Output(하드웨어의 입출력을 제어하는) System(소프트웨어)"
라고 알아두세요. 기존 컴퓨터의 하드웨어와 소프트웨어 상호작용은 이 "BIOS"를 통해서 가능한 것입니다.
즉, 하드웨어 <---> BIOS <---> 소프트웨어(운영체제)
어쨌든 이렇게 "BIOS"에 의해 논리적으로 디스크의 공간이 한 줄인양 주소가 할당이 된 뒤
이제 이 주소에 정보들을 어디에 저장하고, 어떻게 사용할지 등 본격적인 관리를
"파일시스템"이 해주는 것 입니다.
5. 중간 정리
어휴... 나름 처음 공부하시는 분들은 정말 머리가 핑~ 돌 정도로 많은 정보를 알려드렸는데
좀 순서가 뒤죽박죽이라 힘드실테니, 다시 한번 순서대로 중간 정리를 해드릴게요.
1. 기존에 디스크 섹터의 주소를 지정하는 방식은 "CHS(Cylinder-head-Sector)" 방식으로
이름 그대로 "실린더-헤드-섹터" 순으로 주소를 지정해 데이터를 저장하고 사용했다.
2. 하지만 과학 기술이 발전함에 따라 "CHS"의 문제가 점점 심화 되자 이것을 보안하기 위해 새로 도입된 기술이 바로 "LBA(Logical Block Addressing)"이며 이것은 "논리적으로 모든 섹터가 한 줄처럼 있다고 구현해서 쉽게 주소를 지정하는 방식"이다. 그리고 이 "LBA"방식이 현재까지 사용된다
이름 그대로 "실린더-헤드-섹터" 순으로 주소를 지정해 데이터를 저장하고 사용했다.
2. 하지만 과학 기술이 발전함에 따라 "CHS"의 문제가 점점 심화 되자 이것을 보안하기 위해 새로 도입된 기술이 바로 "LBA(Logical Block Addressing)"이며 이것은 "논리적으로 모든 섹터가 한 줄처럼 있다고 구현해서 쉽게 주소를 지정하는 방식"이다. 그리고 이 "LBA"방식이 현재까지 사용된다
3. 이 LBA(Logical Block Addressing)는 "BIOS(Basic Input/Output System)"가 구현해준다
4. 이제 이 "BIOS"가 구현한 "LBA"를 이용해 "파일시스템"이 본격적으로 데이터를 효율적이게 관리를 하고 사용할 수 있게 블록(클러스터)를 계산해주는 것이다.
6. 파일시스템의 추상화 구조(Meta Area, Data Area)
저희는 디스크 주소 지정을 "LBA(Logical Blcok Addressing)"방식으로 한다는 것을
알았으니 앞으론
알았으니 앞으론

이렇게 한 줄로 디스크의 공간을 표시하도록 할게요. 물론 실제 디스크 공간은 저것보다
훠~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~월씬
많다는 것은 아시죠?
그리고 저 섹터들을 이제 "파일시스템"이 "블록(클러스터)"으로 나누면

이렇게 나눠지는 것이죠. 이제부턴 보통 "섹터"라는 말은 거의 안쓰고
"블록" 또는 "클러스터"란 말을 자주 쓸겁니다. 운영체제에선 원래 "블록(클러스터)"단위로 읽고 쓴다고 했죠?
자 그럼 이제 본격적으로 "파일시스템이 어떻게 데이터를 관리하느냐"를 배울 것인데
가장 먼저, 대부분의 "파일시스템"은 데이터를 저장할 때
"메타 지역(Meta Area)"과 "데이터 지역(Data Area)"으로 나눠 저장해 관리합니다.

훠~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~월씬
많다는 것은 아시죠?
그리고 저 섹터들을 이제 "파일시스템"이 "블록(클러스터)"으로 나누면

이렇게 나눠지는 것이죠. 이제부턴 보통 "섹터"라는 말은 거의 안쓰고
"블록" 또는 "클러스터"란 말을 자주 쓸겁니다. 운영체제에선 원래 "블록(클러스터)"단위로 읽고 쓴다고 했죠?
자 그럼 이제 본격적으로 "파일시스템이 어떻게 데이터를 관리하느냐"를 배울 것인데
가장 먼저, 대부분의 "파일시스템"은 데이터를 저장할 때
"메타 지역(Meta Area)"과 "데이터 지역(Data Area)"으로 나눠 저장해 관리합니다.

이렇게 말이죠.
"Data(데이터) Area"는 "유저 데이터"라고도 하며 이름 그대로 우리가 생각하는 "대부분의 데이터"들을 저장하는 공간입니다.
"Meta(메타) Area" 는 뭘까요? 메타(Meta)의 뜻은 "변화중인" , "기존의 한계를 뛰어넘은", "자기가 가진 특징을 가리키는" 뭐 이렇게 많은데요
그 중 여기에 쓰인 뜻은 "자기가 가진 특징을 가리키는" 인 것 같습니다. 즉,
"메타 데이터(Meta data)"는 "자기가 가진 특징을 가리키는 데이터"라
볼 수 있고 "Meta(메타) Area"은 이런 메타 데이터들이 저장되는 장소인 것이죠.
'뭔 소리야??' 싶을 겁니다. 어렵게 생각하지 마시고, "메타 데이터(자기가 가진 특징을 가리키는 데이터)"란 리눅스의 "I-node" 라고 보시면 됩니다.
"I-node"가 뭐였습니까? "Index-node"였죠? 즉, "파일을 빨리 찾기 위한 인덱스"였죠.
그래서 파일의 모든 정보를 가지고 있고, 이 i-node를 보고 그 파일 저장된 디스크 위치를 찾으며 사용하는 겁니다.
이처럼 "Meta Area"는 i-node와 같은
"Meta data(실제 데이터들의 디스크 위치를 기록해 둔 정보)"들을 저장하는 곳입니다.
그래서 "대부분의 파일시스템"은 이렇게 "Meta Area"와 "Data Area"를 나눠서 보관합니다. 메타 데이터를 참조하는 방식을 사용하면 일일이 원하는 데이터를 찾기 위해
시간을 낭비하지 않으니 효율적인 것이죠.
파일시스템의 기능에 대해서 대략적으로도 알고나니 이젠 '디스크엔 파일시스템이
없으면 디스크 역할을 못하겠네?' 라고 생각이 들죠? 그래서 이처럼 "파일시스템"은
"저장공간을 사용한다면 무조건 필요한 소프트웨어"이며 동시에 "운영체제에 무조건 필수적으로 포함 되야함"을 알 수 있습니다.
이제 대부분의 파일시스템의 추상화 구조를 알았겠다.
이제 본격적으로 저희들이 자주 사용하는 파일시스템을 예시를 들며 본격적으로
각 "파일시스템의 구조 특징"을 알아볼까요?
우리가 가장 흔히 접하는 것들엔
지금은 USB에 자주 사용되는 파일시스템 "FAT(File Allocation Table) 16, 32"가 있고(exFAT이란 것도 있습니다!)
윈도우 운영체제에 사용되는 파일 시스템은 NTFS(New Technology File System)가
있습니다. (물론 지금은 더 업그레이드 된 윈도우용 파일시스템이 사용되지만 NTFS가 가장 유명하니깐!)
리눅스 운영체제에 사용되는 파일 시스템으로는 "ext2, etx3, ext4 그리고 xfs"가 있습니다.
사실 이것 말고도 저~~~엉말 많은 파일시스템들이 있는데 지금은
배우는 단계니 이 정도만 하고 넘어갈게요.
제일 먼저 "FAT(File Allocation Table)" 같은 경우
제일 먼저 FAT의 첫 시리즈 "FAT12"는 플로피디스크 용으로 만들어졌지만 이후 "FAT 16"부터 하드디스크 용으로 발전합니다. 물론 지금은 하드디스크의 용량이 너무 커져서 하드디스크엔 "FAT"을 잘 안쓰죠
"Data(데이터) Area"는 "유저 데이터"라고도 하며 이름 그대로 우리가 생각하는 "대부분의 데이터"들을 저장하는 공간입니다.
"Meta(메타) Area" 는 뭘까요? 메타(Meta)의 뜻은 "변화중인" , "기존의 한계를 뛰어넘은", "자기가 가진 특징을 가리키는" 뭐 이렇게 많은데요
그 중 여기에 쓰인 뜻은 "자기가 가진 특징을 가리키는" 인 것 같습니다. 즉,
"메타 데이터(Meta data)"는 "자기가 가진 특징을 가리키는 데이터"라
볼 수 있고 "Meta(메타) Area"은 이런 메타 데이터들이 저장되는 장소인 것이죠.
'뭔 소리야??' 싶을 겁니다. 어렵게 생각하지 마시고, "메타 데이터(자기가 가진 특징을 가리키는 데이터)"란 리눅스의 "I-node" 라고 보시면 됩니다.
"I-node"가 뭐였습니까? "Index-node"였죠? 즉, "파일을 빨리 찾기 위한 인덱스"였죠.
그래서 파일의 모든 정보를 가지고 있고, 이 i-node를 보고 그 파일 저장된 디스크 위치를 찾으며 사용하는 겁니다.
이처럼 "Meta Area"는 i-node와 같은
"Meta data(실제 데이터들의 디스크 위치를 기록해 둔 정보)"들을 저장하는 곳입니다.
그래서 "대부분의 파일시스템"은 이렇게 "Meta Area"와 "Data Area"를 나눠서 보관합니다. 메타 데이터를 참조하는 방식을 사용하면 일일이 원하는 데이터를 찾기 위해
시간을 낭비하지 않으니 효율적인 것이죠.
7. 파일시스템의 종류와 역사
파일시스템의 기능에 대해서 대략적으로도 알고나니 이젠 '디스크엔 파일시스템이
없으면 디스크 역할을 못하겠네?' 라고 생각이 들죠? 그래서 이처럼 "파일시스템"은
"저장공간을 사용한다면 무조건 필요한 소프트웨어"이며 동시에 "운영체제에 무조건 필수적으로 포함 되야함"을 알 수 있습니다.
이제 대부분의 파일시스템의 추상화 구조를 알았겠다.
이제 본격적으로 저희들이 자주 사용하는 파일시스템을 예시를 들며 본격적으로
각 "파일시스템의 구조 특징"을 알아볼까요?
우리가 가장 흔히 접하는 것들엔
지금은 USB에 자주 사용되는 파일시스템 "FAT(File Allocation Table) 16, 32"가 있고(exFAT이란 것도 있습니다!)
윈도우 운영체제에 사용되는 파일 시스템은 NTFS(New Technology File System)가
있습니다. (물론 지금은 더 업그레이드 된 윈도우용 파일시스템이 사용되지만 NTFS가 가장 유명하니깐!)
리눅스 운영체제에 사용되는 파일 시스템으로는 "ext2, etx3, ext4 그리고 xfs"가 있습니다.
사실 이것 말고도 저~~~엉말 많은 파일시스템들이 있는데 지금은
배우는 단계니 이 정도만 하고 넘어갈게요.
제일 먼저 "FAT(File Allocation Table)" 같은 경우
제일 먼저 FAT의 첫 시리즈 "FAT12"는 플로피디스크 용으로 만들어졌지만 이후 "FAT 16"부터 하드디스크 용으로 발전합니다. 물론 지금은 하드디스크의 용량이 너무 커져서 하드디스크엔 "FAT"을 잘 안쓰죠
"FAT" 뒤에 붙은 숫자는 클러스터를 만들 수 있는 "비트의 수" 입니다.
예를 들어, "1 비트"는 "on과 off"로 총 2개 경우의 수가 있고, 2비트는 2의 2승으로 4의 경우의 수가 있고 4비트는 2의 4승으로 16개 경우의 수가 있죠?
같은 원리로 FAT12는 2의 12승의 수 만큼 클러스터(블록)을 가질 수 있다는 뜻이고
FAT32는 2의 32승의 수 만큼 클러스터를 가질 수 있다는 뜻입니다.(물론 자세하게 따지면 또 추가로 몇 개를 더 빼고 계산해야 합니다.)
수가 높을 수록 클러스터를 많이 가질 수 있으니 그 만큼 사용할 수 있는
용량이 더 커지겠죠?
"FAT 32"는 또 기가막히게 외우기 쉽게, 지원하는 "최대 드라이브 크기는 32GB"이고 한 파일당 4GB를 지원합니다. 그래서 USB에 자주 쓰이죠 하지만 한 파일에 4GB밖에 지원을 안하기에, 4GB 이상 크기 파일을 USB에 옮기려 하면 못 옮기고 파일시스템을 바꿔야한다는 설정이 나오는 겁니다.
"FAT" 파일시스템의 구조는

"예약지역", "FAT지역", "데이터지역" 이렇게 크게 3가지로 나뉘어 지는데
"Reserved Area(예약 지역)"은 말 그대로 "예약된 행위 정보들이 들어있는 곳"으로
"부트 블록(Boot Block)"과 "파일시스템 정보 블록(FSINFO{File System INFOmation} Block)" 그리고 "추가적인 예약 공간 블록"으로 또 나뉘어집니다.
"Reserved Area(예약 지역)"은 말 그대로 "예약된 행위 정보들이 들어있는 곳"으로
"부트 블록(Boot Block)"과 "파일시스템 정보 블록(FSINFO{File System INFOmation} Block)" 그리고 "추가적인 예약 공간 블록"으로 또 나뉘어집니다.
"부트 블록(Boot Block)"은 말 그대로 "컴퓨터 부팅에 관련된 정보들이 들어있는 블록"이고
"파일시스템 정보(FSINFO{File System INFOmation} Block)"는
"운영체제에게 알려줄 파일시스템 정보들이 있는 블록" 이고
"파일시스템 정보(FSINFO{File System INFOmation} Block)"는
"운영체제에게 알려줄 파일시스템 정보들이 있는 블록" 이고
"추가적인 예약 공간 블록"은 말 그대로 "추가적으로 예약해두고 싶은 행위 정보를 넣는 공간"입니다.
"FAT Area"는 제가 위에서 언급한 "Meta Area"라고 생각하시면 됩니다.
"FAT(File Allocation Table)" 영역은 말 그대로
"File(파일에 얼마나) Allocation(클러스터가 할당 됐는지 적혀있는) Table(테이블)"으로서
"File(파일에 얼마나) Allocation(클러스터가 할당 됐는지 적혀있는) Table(테이블)"으로서
어떤 파일에 얼마나 많은 공간(클러스터)가 할당됐는지, 어디 있는지, 언제 수정되고 만들어졌는지 등등의 정보들이 들어있는 겁니다.
"Data Area"는 말 그대로 데이터 지역으로, 우리가 흔히 사용하는 파일들 데이터들이
저장되는 공간입니다.
사실 여기까지만 알고나면 똥 싸고 덜 닦은 기분이 드실텐데...
더욱 자세히 설명하기 시작하면 이 포스트가 언제 끝날지 모르겠고 ㅠㅠ
또 너무 리눅스 공부를 위한 취지를 벗어난 부분이기 때문에 훗날 파일시스템 심화적인 내용을 다루게 된다면 그 때 다루도록 하겠습니다.
윈도우 운영체제에 사용되는 파일 시스템
NTFS(New Technology File System)
기존의 "FAT" 파일시스템의 한계점을 돌파한 파일시스템으로 "마이크로소프트" 사에서
만들었습니다.
그래서 당연히 윈도우 운영체제에 기본 탑재된 파일시스템으로
"Windows NT" 부터 사용되었습니다.
"New Technology"란 이름에 걸맞게, 지원하는 디스크의 크기도 256TB까지 지원하고
한 파일 크기 제한도 16TB입니다. 그리고 "디스크 복구 기능"도 있습니다.
또한 서버용으로도 지원이 되죠.
그래서 나중에 리눅스 Quota편에서 배울거지만, "Quota"라고 각 유저에게 일정량만 사용하게 하는 등 디스크 제한도 걸 수 있습니다.
"NTFS"의 구조는

이렇게 "VBR(Volume Boot Record)" 영역과 "MFT(Master File Table)"의 영역
그리고 "Data Area" 이렇게 크게 나눌 수 있는데요.
"VBR(Volume Boot Record)"은
"Volume(공간) Boot(부트를 위한 것들이) Record(기록돼 있는)" 이란 뜻으로
말 그대로 부팅에 관련된 정보들이 저장된 공간입니다.
"MFT(Master File Table)"는
Master(총 관리를 위한) File(파일들에 대한 것들이) Table(기록되는 테이블)
이라고 볼 수 있는데, 그냥 "Meta Area"라고 보시면 됩니다.
"Meta Area"이니까 당연히 파일들의 위치, 정보, 크기 ,이름등 정보가 있습니다.
물론 이렇게만 설명하면
'FAT이랑 다를게 뭐냐!!!' 란 말이 나올 수 밖에 없는데... 완전 다릅니다.
세부적으로 따지면 많이 다른데... 위에 말했다시피 너무 어렵기도 하고 길기때문에
나중에 기회가 될 때 자세히 포스트 하겠습니다 ㅠㅠ
"Data Area"는 뭐 말 그대로 통상적인 데이터들이 있는 곳이죠?
이렇게 수박 겉 핥기식으로 알려줄 거면 뭘 거창하게 파일시스템 구조에 대해
설명을 했느냐! 하실텐데.. 음.. 그냥 파일시스템이란 것에 대해 전체적으로 자연스러운
이해를 돕기 위해 설명하다 보니 포렌식영역까지 건들게 된 것 같습니다...
다시 한번 자세한 포렌식쪽 정보를 기대하고 들어오신 분들에게 사과의 말씀을 드립니다ㅠ
리눅스 운영체제에 사용되는 파일 시스템 "ext2, ext3, ext4 그리고 xfs"
사실 이 리눅스 파일시스템이 바로 이 포스트의 핵심이라고 할 수 있습니다.
왜냐면 지금 저는 리눅스 독학을 위한 포스트를 하고 있으니깐 말이죠!
물론 이것도 매우~~ 자세히는 다루지는 못합니다.. 그래도
각 시리즈마다의 특징과 업그레이드 된 점들에 대해서 설명은 할 수 있습니다.
리눅스 운영체제를 사용하시다 보면 이제 이 "ext"로 시작하는 파일시스템을
많이 접하게 되실텐데요.
최초의 "ext"는 당연히 "ext(1)" 입니다.
"ext(EXTended file system)"의 줄임말로 "유닉스와 리눅스의 역사" 포스트를 보시면
"리누스 토발즈"가 교육용 유닉스인 "미닉스(Minix)"의 한계에 답답해서
유닉스와 호환되는 운영체제를 만든 게 "리눅스"라고 했죠?
리눅스도 초기엔 미닉스에서 사용하던 "MINIX 파일시스템"을 사용했는데 미닉스 파일시스템은 "64MB"라는 매우 적은 저장공간과 파일 글자 이름을 최대 "14 글자"까지 밖에
지원을 못 했습니다..
결국 이런 단점 때문에 "EXT(EXTended file system)"란 "Rémy Card"가 만든 파일시스템을 리눅스 파일시스템으로 채택합니다.
이 첫 버젼 "EXT"는 2GB까지 용량을 지원했고 파일 이름도 255글자까지 가능했습니다.
그리고 "가상파일시스템 (VFS{Virtual File System)}"을 도입했습니다.
"가상파일시스템 VFS"란 원래 각각의 파일시스템마다 서로 데이터를 다루는 방법과 형태가 다르잖아요? 이런 각 파일시스템의 정보들을 일관되게 가상적으로 같은 정보처럼 만들어서 운영체제에서 같이 사용할 수 있게 하는 겁니다.
쉽게 이 "가상파일시스템"은 "통역사"라고 보시면 됩니다.
두 개의 다른 파일시스템을 각각 일본인, 한국인, 그리고 운영체제를 미국인이라고
비유했을 때, 일본인이 "이치고 우마이!"라 썼고, 한국인이 "딸기 맛있엉!"이라 써놨다면
미국인은 "What!?" 이러며 이해를 못할테죠 하지만 한국인, 일본인의 글을
"가상파일시스템"이 "Strawberries are so delicious!"처럼 영어로 통일해버리면
운영체제(미국인)가 이해하고 쓸 수 있겠죠?
어쨌든 "Minix" 파일시스템에 비하면 말도 안되게 훌륭한 성능을 가진 "EXT"였지만 그럼에도 불구하고 늘어난 2GB도 너무나 적은 용량이였고, 사용할 수록 디스크에 "단편화"가 일어나는 치명적 단점이 있었습니다.
"단편화"란 쉽게 "저장공간 중간중간에 빈 공간이 생기는 현상"을 말합니다.
저~~ 위에서 파일시스템 역할 중, "파일의 크기가 변하거나 삭제 됐을 때 생기는 공간
문제"에 대해서 얘기 했었는데 그 문제를 "단편화" 라고 합니다.
이 그림에서 보이는 저 중간중간 흰 구멍 같은 것이 바로 "단편화"라는 것이죠~
이건 메모리편에서도 자주 나오는 개념으로, 메모리에서도 비슷합니다.
어쨌든, 이러한 "EXT"문제를 보완하여 바로 나온 것이 바로!
"EXT 2(EXTended file system 2)"입니다.
"EXT 2(EXTended file system 2)"
"2GB"라는 적은 용량의 단점을 보완해 나온 "EXT2"는 "2TB"까지 지원하며 한 파일의 크기도 "16GB"까지 지원했습니다. 그리고 리눅스의 특징중 하나인 "i-node" 기능을 이 때부터 지원하기 시작합니다. 그래서 리눅스의 본격적인 파일시스템의 형태를 띄기 시작한 것은
"EXT 2"부터라고 보시면 됩니다.
"ext2" 파일시스템 부터 Inode라는 시스템을 도입한 것 외에도, 지금까지 설명했던 다른
파일시스템이랑 비교했을 때 디스크를 관리하는 방법에서 차별화 된 것이 더 있습니다.
바로 "블록 그룹(Block Group)" 이라는 것을 사용하는 점이 다른데요. 기존의 운영체제가 사용하는 단위는 여러개의 섹터를 합친 "블록(클러스터)"이라고 했었잖아요? 그 블록을 또 한 번 더 뭉친 겁니다!
즉,
(섹터+섹터+...) = "블록(클러스터)"
(블록+블록+....) = "블록 그룹"
이렇게 되는 것이죠.
"ext2" 이상 파일시스템은 디스크의 공간을 맨 앞에 부팅을 위한
"부트 섹터(Boot Sector)"와, "블록 그룹"으로 나눕니다. 그리고
"블록 그룹" 안에 들어있는 블록의 수는 맨 마지막 블록 그룹 빼곤
다 일정하구요(맨 마지막 블록 그룹은 "나머지 블록 수"니깐요~)
그림을 함 보고 가시죠~

이런 식으로 "EXT2" 파일시스템의 디스크는 맨 앞이 "부트 섹터"이고 나머진 "블록 그룹"으로 이루어진 겁니다.
왜 맨 앞은 "블록"이 아닌 "섹터"일까요? 그야~ 블록 크기까지는 필요가 없으니까
섹터라 했겠죠?
그리고 "블록 그룹"의 구성은 그 밑에 표시한 것처럼
"슈퍼 블록(Super Block)", "그룹 디스크립터 테이블(Group Descriptor Table)",
"블록 비트맵(Block Bitmap)", "아이노드 비트맵(Inode Bitmap)",
"아이노드 테이블(Inode Table)", "데이터(DATA)"로 이루어져 있습니다.
자세하게 다루면 이것도 너무 어려워지기 때문에 각 블록이 무슨 역할인지만
설명할게요~
"슈퍼 블록(Super Block)"의 "Super"란 단어는 Supervisor(관리자)나 Superintendent(특정 부서나 지역에 총 책임자)란 단어에 붙는 수식어처럼 "총 관리"이런 느낌이라 보시면 됩니다.
그럼 "슈퍼 블록" 이 무슨 블록인지 대충 느낌이 오실 겁니다. 네 그렇습니다. 모~든 블록에 해당되는 공통된 정보들을 관리하고 들어있는 블록입니다.
모든 블록의 정보라는 건, "블록의 크기(몇 개의 섹터로 이루어졌는가)", "총 블럭의 개수",
"블록 그룹의 개수", "블록 그룹 내 블록과 아이노드 개수" 등 말 그대로 모든 블록에 공통적으로 해당되는 정보입니다.
그래서 어떻게 보면 파일시스템에서 "제일 중요한 블록"으로서 "첫 번째 블록 그룹"의
"맨 앞"에 있습니다. 그러나 그 만큼 중요하기에 다른 모든 "블록 그룹 맨 앞에도 복사본"이 있습니다. 물론 사용은 첫 번째 블록그룹에 속한 것만 합니다.
"그룹 디스크립터 테이블(Group Descriptor Table)"의 "Descriptor"란 단어는
컴퓨터공학에서 "다른 데이터가 어떻게 저장됐는지를 가르쳐주는 데이터의 일부"란 뜻으로
그냥 "Meta Data"라고 보시면 됩니다.
뜻을 이제 적용해서 다시 해석해보면
Group(블록 그룹) Descriptor(데이터들이 어떻게 저장됐는지를 알려주는 데이터가) Table(써있는 테이블) 이렇게 볼 수 있네요~
위에 설명한대로 이 "그룹 디스크립터 테이블"에는 "Block Bitmap"의 번호(위치), "Inode Bitmap"의 번호(위치), "블록 그룹안에 있는 빈 블럭, 빈 디렉터러 수", "Inode 수", "Inode 테이블 번호(위치)"등
블럭 그룹들의 데이터들이 어떻게 저장 됐는지를 알려주는 데이터들이 들어 있습니다.
이 "슈퍼 블록" 다음에 위치하는 "그룹 디스크립터 테이블"도 슈퍼블록 못지않게 중요하기에
슈퍼블록처럼 모든 블록 그룹에 복사본이 있습니다.
그 다음은 "블록 비트맵(Block Bitmap)"과 "아이노드 비트맵(Inode bitmap)"이 오는데
여기서 "비트맵(Bitmap)"이란
아는 사람은 다 아는 그 "비트맵" 맞습니다. 뭔 소리냐고요? 그림을 보면 아~ 하실겁니다.
*
이거 말하는 겁니다. 아하~ 이제 아시겠죠?
말 그대로 0은 없는 것, 1은 있다고 표시하는 건데요.
그럼 "블록 비트맵"과 "아이노드 비트맵"은 뭘 나타내는 걸까요?
네 바로 각각 "사용되고 있는 블록과 아이노드가 몇 개냐"를 나타내는 것 입니다.
그리고 각각 블록과 아이노드를 개당 "1Bit"로 계산합니다.
또한 "블록 비트맵(Block bitmap)"과 "아이노드 비트맵(inode bitmap)"에는 1 Block만큼 공간이 배정 됩니다.
윗글론 이해가 힘들테니 예를 들어 설명해볼게요.
자 처음 섹터 한 개당 크기는 "512Byte"이라 치구, 언급했던 "슈퍼블록"에서 각 블록은
2개의 섹터로 이루어져 있다고 설정했다 칩시다.
그러면 "한 개의 블록"은 2개의 섹터로 이루어져 있고 512Byte * 2니까 "1KB"이죠?
그럼
"블록 비트맵"은 1개의 블럭만큼 용량이 주어지니 총 공간은"1KB=1024Byte= 8192Bit"
입니다. 그러면 각 블록 그룹마다 있는 "블록 비트맵"은 총 8196개까지 블럭의 사용의 유무를 셀 수 있는 겁니다.
그럼 이번엔 디스크 섹터당 크기가 1KB이라고 치고, "슈퍼블록"에서 한 블럭의 크기를
4개의 섹터로 설정했다고 칩시다.
그럼 "아이노드 비트맵"도 1 블럭만큼 공간이 주어지니 총 4KB만큼 공간이 있죠?
그래서 "아이노드 비트맵"은 아이노드의 개수를 1*8*1024*4 개까지 셀 수 있는 겁니다.(1bit가 1개의 아이노드니깐)
이제 "블록 비트맵"과 "아이노드 비트맵"이 뭔지 아시겠죠?
또한 블록 비트맵과 아이노드 비트맵은 위 예시처럼, 섹터크기와 블록 크기에 따라
크기가 변할 수 있기 때문에 블록 그룹내에 고정적으로 위치하지 않습니다.
그래서!! "그룹 디스크립터 테이블"에 블록 비트맵과 아이노드 비트맵의 번호(위치)가
적혀 있던 겁니다.
"아이노드 테이블(Inode Table)"은 이름 그대로 "아이노드들이 기록된 테이블"
입니다. 실질적으로 여기에 적힌 아이노드를 보고서 파일을 찾고 분류하고 하는 것이죠.
그리고 "ext2"에선 기본적으로 아이노드 한 개의 크기가 "128Byte"이기 때문에
섹터의 크기가 512byte이고 블럭이 2개의 섹터로 이루어졌고
"아이노드 테이블"의 블럭의 수가 2개일때, "아이노드 테이블"은 총 2048byte의 공간이 있어서 16개(2048/128)의 아이노드 정보가 적힐 수 있는 것 입니다.
자 나머지가 공간은 바로 "Data" 블록이죠. 이름 그대로 저희들이 생각하는 데이터들이
저장되는 블록입니다.
"ext2"부턴 "블록그룹"을 통해서 연관된 데이터들끼리 더욱 분류를 할 수 있기에
그만큼 "단편화" 현상을 줄였습니다. 생각해보세요~

이렇게 전체 영역에 골고루 "단편화(똥)"이 생기는 것 보단

이렇게 좁은 부분에만 "단편화(똥)"이 생기는 게 낫잖아요?
이후 EXT 2는 지원하는 디스크 용량 크기도 32TB까지 늘리고, 한 파일의 크기도 2TB까지로
늘렸습니다. 이렇듯 거의 완벽해 보이는 EXT 2였지만 그래도 여전히 단편화 증상을 해결하지는 못했고, 디스크에 데이터를 저장하는 동안 전원이 끊기면 심각한 손상이 일어난다는
큰 문제가 있었습니다(복구가 안됨)
그래서 이러한 복구 문제를 해결한 파일시스템이 나왔으니 그것이 바로!
"EXT 3(EXTended file system 3)"!!
만들었습니다.
그래서 당연히 윈도우 운영체제에 기본 탑재된 파일시스템으로
"Windows NT" 부터 사용되었습니다.
"New Technology"란 이름에 걸맞게, 지원하는 디스크의 크기도 256TB까지 지원하고
한 파일 크기 제한도 16TB입니다. 그리고 "디스크 복구 기능"도 있습니다.
또한 서버용으로도 지원이 되죠.
그래서 나중에 리눅스 Quota편에서 배울거지만, "Quota"라고 각 유저에게 일정량만 사용하게 하는 등 디스크 제한도 걸 수 있습니다.
"NTFS"의 구조는

이렇게 "VBR(Volume Boot Record)" 영역과 "MFT(Master File Table)"의 영역
그리고 "Data Area" 이렇게 크게 나눌 수 있는데요.
"VBR(Volume Boot Record)"은
"Volume(공간) Boot(부트를 위한 것들이) Record(기록돼 있는)" 이란 뜻으로
말 그대로 부팅에 관련된 정보들이 저장된 공간입니다.
"MFT(Master File Table)"는
Master(총 관리를 위한) File(파일들에 대한 것들이) Table(기록되는 테이블)
이라고 볼 수 있는데, 그냥 "Meta Area"라고 보시면 됩니다.
"Meta Area"이니까 당연히 파일들의 위치, 정보, 크기 ,이름등 정보가 있습니다.
물론 이렇게만 설명하면
'FAT이랑 다를게 뭐냐!!!' 란 말이 나올 수 밖에 없는데... 완전 다릅니다.
세부적으로 따지면 많이 다른데... 위에 말했다시피 너무 어렵기도 하고 길기때문에
나중에 기회가 될 때 자세히 포스트 하겠습니다 ㅠㅠ
"Data Area"는 뭐 말 그대로 통상적인 데이터들이 있는 곳이죠?
이렇게 수박 겉 핥기식으로 알려줄 거면 뭘 거창하게 파일시스템 구조에 대해
설명을 했느냐! 하실텐데.. 음.. 그냥 파일시스템이란 것에 대해 전체적으로 자연스러운
이해를 돕기 위해 설명하다 보니 포렌식영역까지 건들게 된 것 같습니다...
다시 한번 자세한 포렌식쪽 정보를 기대하고 들어오신 분들에게 사과의 말씀을 드립니다ㅠ
리눅스 운영체제에 사용되는 파일 시스템 "ext2, ext3, ext4 그리고 xfs"
사실 이 리눅스 파일시스템이 바로 이 포스트의 핵심이라고 할 수 있습니다.
왜냐면 지금 저는 리눅스 독학을 위한 포스트를 하고 있으니깐 말이죠!
물론 이것도 매우~~ 자세히는 다루지는 못합니다.. 그래도
각 시리즈마다의 특징과 업그레이드 된 점들에 대해서 설명은 할 수 있습니다.
리눅스 운영체제를 사용하시다 보면 이제 이 "ext"로 시작하는 파일시스템을
많이 접하게 되실텐데요.
최초의 "ext"는 당연히 "ext(1)" 입니다.
"ext(EXTended file system)"의 줄임말로 "유닉스와 리눅스의 역사" 포스트를 보시면
"리누스 토발즈"가 교육용 유닉스인 "미닉스(Minix)"의 한계에 답답해서
유닉스와 호환되는 운영체제를 만든 게 "리눅스"라고 했죠?
리눅스도 초기엔 미닉스에서 사용하던 "MINIX 파일시스템"을 사용했는데 미닉스 파일시스템은 "64MB"라는 매우 적은 저장공간과 파일 글자 이름을 최대 "14 글자"까지 밖에
지원을 못 했습니다..
결국 이런 단점 때문에 "EXT(EXTended file system)"란 "Rémy Card"가 만든 파일시스템을 리눅스 파일시스템으로 채택합니다.
이 첫 버젼 "EXT"는 2GB까지 용량을 지원했고 파일 이름도 255글자까지 가능했습니다.
그리고 "가상파일시스템 (VFS{Virtual File System)}"을 도입했습니다.
"가상파일시스템 VFS"란 원래 각각의 파일시스템마다 서로 데이터를 다루는 방법과 형태가 다르잖아요? 이런 각 파일시스템의 정보들을 일관되게 가상적으로 같은 정보처럼 만들어서 운영체제에서 같이 사용할 수 있게 하는 겁니다.
쉽게 이 "가상파일시스템"은 "통역사"라고 보시면 됩니다.
두 개의 다른 파일시스템을 각각 일본인, 한국인, 그리고 운영체제를 미국인이라고
비유했을 때, 일본인이 "이치고 우마이!"라 썼고, 한국인이 "딸기 맛있엉!"이라 써놨다면
미국인은 "What!?" 이러며 이해를 못할테죠 하지만 한국인, 일본인의 글을
"가상파일시스템"이 "Strawberries are so delicious!"처럼 영어로 통일해버리면
운영체제(미국인)가 이해하고 쓸 수 있겠죠?
어쨌든 "Minix" 파일시스템에 비하면 말도 안되게 훌륭한 성능을 가진 "EXT"였지만 그럼에도 불구하고 늘어난 2GB도 너무나 적은 용량이였고, 사용할 수록 디스크에 "단편화"가 일어나는 치명적 단점이 있었습니다.
"단편화"란 쉽게 "저장공간 중간중간에 빈 공간이 생기는 현상"을 말합니다.
저~~ 위에서 파일시스템 역할 중, "파일의 크기가 변하거나 삭제 됐을 때 생기는 공간
문제"에 대해서 얘기 했었는데 그 문제를 "단편화" 라고 합니다.
이 그림에서 보이는 저 중간중간 흰 구멍 같은 것이 바로 "단편화"라는 것이죠~
이건 메모리편에서도 자주 나오는 개념으로, 메모리에서도 비슷합니다.
어쨌든, 이러한 "EXT"문제를 보완하여 바로 나온 것이 바로!
"EXT 2(EXTended file system 2)"입니다.
"EXT 2(EXTended file system 2)"
"2GB"라는 적은 용량의 단점을 보완해 나온 "EXT2"는 "2TB"까지 지원하며 한 파일의 크기도 "16GB"까지 지원했습니다. 그리고 리눅스의 특징중 하나인 "i-node" 기능을 이 때부터 지원하기 시작합니다. 그래서 리눅스의 본격적인 파일시스템의 형태를 띄기 시작한 것은
"EXT 2"부터라고 보시면 됩니다.
"ext2" 파일시스템 부터 Inode라는 시스템을 도입한 것 외에도, 지금까지 설명했던 다른
파일시스템이랑 비교했을 때 디스크를 관리하는 방법에서 차별화 된 것이 더 있습니다.
바로 "블록 그룹(Block Group)" 이라는 것을 사용하는 점이 다른데요. 기존의 운영체제가 사용하는 단위는 여러개의 섹터를 합친 "블록(클러스터)"이라고 했었잖아요? 그 블록을 또 한 번 더 뭉친 겁니다!
즉,
(섹터+섹터+...) = "블록(클러스터)"
(블록+블록+....) = "블록 그룹"
이렇게 되는 것이죠.
"ext2" 이상 파일시스템은 디스크의 공간을 맨 앞에 부팅을 위한
"부트 섹터(Boot Sector)"와, "블록 그룹"으로 나눕니다. 그리고
"블록 그룹" 안에 들어있는 블록의 수는 맨 마지막 블록 그룹 빼곤
다 일정하구요(맨 마지막 블록 그룹은 "나머지 블록 수"니깐요~)
그림을 함 보고 가시죠~

이런 식으로 "EXT2" 파일시스템의 디스크는 맨 앞이 "부트 섹터"이고 나머진 "블록 그룹"으로 이루어진 겁니다.
왜 맨 앞은 "블록"이 아닌 "섹터"일까요? 그야~ 블록 크기까지는 필요가 없으니까
섹터라 했겠죠?
그리고 "블록 그룹"의 구성은 그 밑에 표시한 것처럼
"슈퍼 블록(Super Block)", "그룹 디스크립터 테이블(Group Descriptor Table)",
"블록 비트맵(Block Bitmap)", "아이노드 비트맵(Inode Bitmap)",
"아이노드 테이블(Inode Table)", "데이터(DATA)"로 이루어져 있습니다.
자세하게 다루면 이것도 너무 어려워지기 때문에 각 블록이 무슨 역할인지만
설명할게요~
"슈퍼 블록(Super Block)"의 "Super"란 단어는 Supervisor(관리자)나 Superintendent(특정 부서나 지역에 총 책임자)란 단어에 붙는 수식어처럼 "총 관리"이런 느낌이라 보시면 됩니다.
그럼 "슈퍼 블록" 이 무슨 블록인지 대충 느낌이 오실 겁니다. 네 그렇습니다. 모~든 블록에 해당되는 공통된 정보들을 관리하고 들어있는 블록입니다.
모든 블록의 정보라는 건, "블록의 크기(몇 개의 섹터로 이루어졌는가)", "총 블럭의 개수",
"블록 그룹의 개수", "블록 그룹 내 블록과 아이노드 개수" 등 말 그대로 모든 블록에 공통적으로 해당되는 정보입니다.
그래서 어떻게 보면 파일시스템에서 "제일 중요한 블록"으로서 "첫 번째 블록 그룹"의
"맨 앞"에 있습니다. 그러나 그 만큼 중요하기에 다른 모든 "블록 그룹 맨 앞에도 복사본"이 있습니다. 물론 사용은 첫 번째 블록그룹에 속한 것만 합니다.
"그룹 디스크립터 테이블(Group Descriptor Table)"의 "Descriptor"란 단어는
컴퓨터공학에서 "다른 데이터가 어떻게 저장됐는지를 가르쳐주는 데이터의 일부"란 뜻으로
그냥 "Meta Data"라고 보시면 됩니다.
뜻을 이제 적용해서 다시 해석해보면
Group(블록 그룹) Descriptor(데이터들이 어떻게 저장됐는지를 알려주는 데이터가) Table(써있는 테이블) 이렇게 볼 수 있네요~
위에 설명한대로 이 "그룹 디스크립터 테이블"에는 "Block Bitmap"의 번호(위치), "Inode Bitmap"의 번호(위치), "블록 그룹안에 있는 빈 블럭, 빈 디렉터러 수", "Inode 수", "Inode 테이블 번호(위치)"등
블럭 그룹들의 데이터들이 어떻게 저장 됐는지를 알려주는 데이터들이 들어 있습니다.
이 "슈퍼 블록" 다음에 위치하는 "그룹 디스크립터 테이블"도 슈퍼블록 못지않게 중요하기에
슈퍼블록처럼 모든 블록 그룹에 복사본이 있습니다.
그 다음은 "블록 비트맵(Block Bitmap)"과 "아이노드 비트맵(Inode bitmap)"이 오는데
여기서 "비트맵(Bitmap)"이란
아는 사람은 다 아는 그 "비트맵" 맞습니다. 뭔 소리냐고요? 그림을 보면 아~ 하실겁니다.
*

이거 말하는 겁니다. 아하~ 이제 아시겠죠?
말 그대로 0은 없는 것, 1은 있다고 표시하는 건데요.
그럼 "블록 비트맵"과 "아이노드 비트맵"은 뭘 나타내는 걸까요?
네 바로 각각 "사용되고 있는 블록과 아이노드가 몇 개냐"를 나타내는 것 입니다.
그리고 각각 블록과 아이노드를 개당 "1Bit"로 계산합니다.
또한 "블록 비트맵(Block bitmap)"과 "아이노드 비트맵(inode bitmap)"에는 1 Block만큼 공간이 배정 됩니다.
윗글론 이해가 힘들테니 예를 들어 설명해볼게요.
자 처음 섹터 한 개당 크기는 "512Byte"이라 치구, 언급했던 "슈퍼블록"에서 각 블록은
2개의 섹터로 이루어져 있다고 설정했다 칩시다.
그러면 "한 개의 블록"은 2개의 섹터로 이루어져 있고 512Byte * 2니까 "1KB"이죠?
그럼
"블록 비트맵"은 1개의 블럭만큼 용량이 주어지니 총 공간은"1KB=1024Byte= 8192Bit"
입니다. 그러면 각 블록 그룹마다 있는 "블록 비트맵"은 총 8196개까지 블럭의 사용의 유무를 셀 수 있는 겁니다.
그럼 이번엔 디스크 섹터당 크기가 1KB이라고 치고, "슈퍼블록"에서 한 블럭의 크기를
4개의 섹터로 설정했다고 칩시다.
그럼 "아이노드 비트맵"도 1 블럭만큼 공간이 주어지니 총 4KB만큼 공간이 있죠?
그래서 "아이노드 비트맵"은 아이노드의 개수를 1*8*1024*4 개까지 셀 수 있는 겁니다.(1bit가 1개의 아이노드니깐)
이제 "블록 비트맵"과 "아이노드 비트맵"이 뭔지 아시겠죠?
또한 블록 비트맵과 아이노드 비트맵은 위 예시처럼, 섹터크기와 블록 크기에 따라
크기가 변할 수 있기 때문에 블록 그룹내에 고정적으로 위치하지 않습니다.
그래서!! "그룹 디스크립터 테이블"에 블록 비트맵과 아이노드 비트맵의 번호(위치)가
적혀 있던 겁니다.
"아이노드 테이블(Inode Table)"은 이름 그대로 "아이노드들이 기록된 테이블"
입니다. 실질적으로 여기에 적힌 아이노드를 보고서 파일을 찾고 분류하고 하는 것이죠.
그리고 "ext2"에선 기본적으로 아이노드 한 개의 크기가 "128Byte"이기 때문에
섹터의 크기가 512byte이고 블럭이 2개의 섹터로 이루어졌고
"아이노드 테이블"의 블럭의 수가 2개일때, "아이노드 테이블"은 총 2048byte의 공간이 있어서 16개(2048/128)의 아이노드 정보가 적힐 수 있는 것 입니다.
자 나머지가 공간은 바로 "Data" 블록이죠. 이름 그대로 저희들이 생각하는 데이터들이
저장되는 블록입니다.
"ext2"부턴 "블록그룹"을 통해서 연관된 데이터들끼리 더욱 분류를 할 수 있기에
그만큼 "단편화" 현상을 줄였습니다. 생각해보세요~

이렇게 전체 영역에 골고루 "단편화(똥)"이 생기는 것 보단

이렇게 좁은 부분에만 "단편화(똥)"이 생기는 게 낫잖아요?
이후 EXT 2는 지원하는 디스크 용량 크기도 32TB까지 늘리고, 한 파일의 크기도 2TB까지로
늘렸습니다. 이렇듯 거의 완벽해 보이는 EXT 2였지만 그래도 여전히 단편화 증상을 해결하지는 못했고, 디스크에 데이터를 저장하는 동안 전원이 끊기면 심각한 손상이 일어난다는
큰 문제가 있었습니다(복구가 안됨)
그래서 이러한 복구 문제를 해결한 파일시스템이 나왔으니 그것이 바로!
"EXT 3(EXTended file system 3)"!!
"Ext3" 파일시스템 부터는 "저널링 기술(Journaling)"을 이용해 백업 및 복구 능력을
갖추게 됐는데요, 이렇듯 저널링 기술을 사용하는 파일시스템을 "저널링 파일시스템"이라고 합니다.
"저널링(Journaling)"기술은 어렵게 생각할 건 없어요. "저널(journal)"이란 영어의 뜻,
"매일 무엇을 했는지 적어놓은 기록"이란 뜻만 알고나면 바로 이해가 됩니다.
"저널링(Journaling)"기술은 어렵게 생각할 건 없어요. "저널(journal)"이란 영어의 뜻,
"매일 무엇을 했는지 적어놓은 기록"이란 뜻만 알고나면 바로 이해가 됩니다.
원래 "저널(journal)"이란 뜻대로 "저널링 기술"은, 항상 디스크에 정보를 변경하기 전에 변경사항들을 "저널"이라고 부르는 로그공간에 미리 기록을 해두는 겁니다. 뭐 어디에 무엇을 저장을 했다 이런 기록을 말이죠.
그래서 "기록(로그)"을 남겨뒀기 때문에 디스크에 정보를 저장하던 중 전원이 끊기거나 문제가 발생했어도 "저널 로그"를 보고 다시 복구할 수 있는 겁니다.
뭐 예시를 들자면 쇼핑하기 전에 구매할 리스트를 미리 적어놓고 가지고 가면, 마트에 도착했을 때 갑자기 뭘 사야할 지 기억이 안나도 리스트를 보고 제대로 살 수 있는 것과 마찬가지인 것이죠.
"EXT3"은 EXT2와 호환이 되게 만들었기 때문에 저널링 기술을 지원하는 거 외엔 "ext2"와 거의 비슷합니다. 그래서 지원하는 디스크 크기나 파일 크기도 EXT2와 비슷하다고 보시면 됩니다.
"EXT 4(EXTended file system 4)"
"EXT 4(EXTended file system 4)"
EXT4는 이름만 봐도 알 수 있듯이 EXT3의 업그레이드 버젼 같은 겁니다.
그래서 EXT3와 호환이 되죠. 그리고 업그레이드 버젼이기 때문에 저널링 기술도 더 업글레이드 됐고, 단편화 증상도 더 줄었습니다.
그리고 가장 주목할 점은 역시 지원하는 용량이 매우 커진 것인데요.
최대 "1엑사 바이트의 디스크 크기"와 "파일당 16테비 바이트"를 지원한다네요!
그래서 EXT3와 호환이 되죠. 그리고 업그레이드 버젼이기 때문에 저널링 기술도 더 업글레이드 됐고, 단편화 증상도 더 줄었습니다.
그리고 가장 주목할 점은 역시 지원하는 용량이 매우 커진 것인데요.
최대 "1엑사 바이트의 디스크 크기"와 "파일당 16테비 바이트"를 지원한다네요!
"1엑사 바이트"는 이제 테라->페타->'엑사'이구
"테비 바이트"는 테라바이트의 2진수 버젼이라고 하네요. 2의 40승이라고 하는데 테라바이트로 환산하면 대략 1.09951테라바이트라나? 음... 계산은 여러분들이 ㅎㅎ
"테비 바이트"는 테라바이트의 2진수 버젼이라고 하네요. 2의 40승이라고 하는데 테라바이트로 환산하면 대략 1.09951테라바이트라나? 음... 계산은 여러분들이 ㅎㅎ
이렇듯 "EXT 4"는 매우 큰 용량을 지원하며 ext3 업그레이드 버젼이라 현재 대부분 리눅스
배포판에서는 이 "EXT 4"를 기본 파일시스템으로 많이 사용하고 있습니다.
배포판에서는 이 "EXT 4"를 기본 파일시스템으로 많이 사용하고 있습니다.
"XFS"(Centos 7이상부터)
1993년 실리콘 그래픽스가 만든 64비트 저널링 파일시스템이며
리눅스에서 "ext시리즈" 파일 시스템 다음으로 가장 많이 쓰이는 파일시스템입니다.
"레드햇 리눅스"은 7버젼부터 기본 파일시스템으로 정식 채택됐으며 당연히
복사버젼인 "Centos"도 7버젼부터 기본 파일시스템으로 채택됐습니다.
"레드햇 리눅스"은 7버젼부터 기본 파일시스템으로 정식 채택됐으며 당연히
복사버젼인 "Centos"도 7버젼부터 기본 파일시스템으로 채택됐습니다.
제일 눈에 띄는 장점은 다른 파일시스템과 비교해서 속도가 매우 빠른 것"
이라 할 수 있네요.
현재 저희가 쓰는 Centos는 7버전 이상이라 XFS가 기본 파일시스템이지만
리눅스마스터 시험은 Centos 6.9버전까지만 나오므로 기본 파일시스템이 "XFS"가
아니란 걸 알아두세요~
이라 할 수 있네요.
현재 저희가 쓰는 Centos는 7버전 이상이라 XFS가 기본 파일시스템이지만
리눅스마스터 시험은 Centos 6.9버전까지만 나오므로 기본 파일시스템이 "XFS"가
아니란 걸 알아두세요~
하.. 이번 포스트는 진짜 5일동안 했네요.. 원래 제 성격이 모르는 거 하나 있으면 그냥 넘어가질 못해서... 이렇게 길게 포스트를 하게 된 것 같습니다..!
아 그리고 인후두염에 걸려서ㅠㅠ 3일간 포스트를 못해서 더 늦게 한 것도 있슴다 ㅠㅠ
여러분들 건강 잘 챙기세요... 진짜 아픈 뒤에야 건강이 얼마나 소중한지 깨닫는 것 같아요~
블로그 포스트 좋아요, 팔로우는 매우 큰 도움이 되며!! 네이버 블로그 공감클릭도 큰 도움이 됩니당!! 그럼 힘들게 디스크, 파일시스템에서 이해했으니 이제 본격적으로
"리눅스 파일시스템"과 마운트, RAID에 대해서 포스트 하도록 하겠습니다~
잘보구갑니다~
답글삭제넵!
삭제RHCSA 공부하면서 리눅스 파일시스템 공부하려다 좋은 강의글 보고 가요.
답글삭제엄청난 내용 글 감사합니다. (__ )
도움이 됐다니 정말 다행입니닷!!
삭제진짜 엄청나네요;; 정말 꼼꼼하시다는게 느껴지는 포스트였습니다. 감사합니다.
답글삭제도움이 됐다니 다행입니다! 따뜻한 댓글 감사해요~!
삭제좋은 글 감사합니다.
답글삭제파일시스템의 전반적인 것을 이해하는데 도움이 되었습니다.
저야말로 도움이 돼 다행입니다!
삭제서버에 대해 하나도 모르고 봤는데 쏙쏙 이해가 잘 됐어요! 감사합니다:)♥
답글삭제도움이 됐다니 정말 다행입니다!! 따듯한 댓글 감사드려요!
삭제감사합니다! 존경스럽네요
답글삭제도움이 돼 다행입니다!!!
삭제감사...합니다...
답글삭제도움이 돼 다행입니다!
삭제덕분에 리눅스 파일 시스템에 대해 완벽하게 이해할 수 있었어요 정말 감사합니다!
답글삭제정말 이 포스트 쓰느라 엄청 고생했었는데,정말 다행입니다 ㅠㅠ
삭제감사합니다 정말정말
답글삭제도움이 돼 정말정말 다행입니다!
삭제lvm 포스트 보다가 여기 들어까지 오게 됐는데요..
답글삭제전 블로그 포스트하다가 길어지면 포기하게 되던데 대단하십니당
설명이 정말 친절해서 이해가 잘 됐어요 감사합니다!
제 노력이 도움이 돼 다행입니다! ㅎㅎ 따뜻한 댓글 감사합니다~
삭제정말 감사드립니다!
답글삭제도움이 돼 다행입니다!!
삭제감사합니다..
답글삭제따뜻한 댓글 감사합니다!
삭제감사합니당..ㅎ
답글삭제저도 감사합니다~!
삭제예시와 함께 설명해주셔서 쭉 읽으며 쉽게 이해가 갔습니다 감사합니다!!
답글삭제예시를 만드느라 당시 엄청 시간을 투자했었는데, 도움이 됐다니 정말 다행이에요!!
삭제와 너무 고마워서 댓글달라고 블로거라는거 가입했습니다. 정말 감사드려요!
답글삭제세상에... 댓글을 달아주시려 가입까지 하시다니 ㅠㅠ 저도 정말 감사드립니다!
삭제잘 읽었습니다. 내용이 많이 생소해서 어렵네요. 나중에 다시 찾아올듯 합니다. ㅎㅎ
답글삭제파일시스템에 대해서 배우는 게 사실 많이 어렵긴 합니다.. 나중에 다시 찾아오실 땐 꼭 도움이 되길 바랄게요!
삭제감사합니다! 공부에 많은 도움이 됐습니다
답글삭제따뜻한 댓글 감사합니다!! 도움이 돼 다행입니다~!
삭제잘 봤습니다! 감사합니다!
답글삭제잘 보셨다니 다행입니다!
삭제너무 쉬운 설명 감사합니다..
답글삭제쉽게 도움이 됐다니 정말 다행입니다!
삭제항상 궁굼했던 내용인데 정말 쉽게 잘 설명하시네요.
답글삭제감사합니다!
도움이 돼 다행입니다! 따뜻한 댓글 감사합니다~
삭제그림까지 한땀한땀 만드셨네요. 글에서 정성과 애정이 가득 담겨있다고 느껴집니다.. 잘 봤습니다 ㅎㅎ
답글삭제